Percolator: Large-scale Incremental Processing Using Distributed Transactions and Notifications
好久没学习了,学点想学的。本次内容是分布式事务Percolator, 不翻译论文,没有算法细节,只记录自己的理解。
Percolator 和 2PC
2PC
两阶段提交协议中包含两种角色,Coordinator和Participant。协调者负责整个协议的推进,使得多个参与者最终达到一致的决议。参与者响应协调者的请求,根据协调者的请求完成 prepare 操作及 commit/abort 操作。
2PC协议保证事务的原子性(ACD),并未对隔离性(I)做任何实现,依赖单机事务(ACD)。Coordinator,显然是关键路径,可能成为单点瓶颈,或者宕机问题阻塞事务流程。
Percolator
本身其实算一种经过优化的二阶段提交的实现,比如:
- 对锁的使用进行优化,引入Primary-Secondary二级锁,去除了对Coordinator的依赖。
- 提供了完整的ACID事务语义实现,并且支持MVCC(依赖时间戳服务)
Percolator协议细节
Percolator系统主要有三部分组成:
-
Client,发起事务的客户端,Client 是整个协议的控制中心,是两阶段提交的协调者(Coordinator)。
-
TO,Time Observer,分配时间戳,提供全局唯一且递增的时间戳,实现MVCC
-
Bigtable,提供单机单行事务,数据存储在Bigtable中,包含数据本身以及附带的一些属性。
lock + write + data: for transaction,lock表示cell被事务持有,write表示数据的可见性notify + ack: for watcher or notifier
从外部看,Percolator以SDK的提供给业务方使用。提供事务以及R/W。模型类似于 Begin Txn → Sets of RW Operations → Commit or About or Rollback其中Bigtable最为持久化组件屏蔽了底层Tablet Server Data Sharding的细节,事务中的每一个写操作或者读后写(统称为Write)操作都视为分布式事务的参与者,而这些操作最后可能会分派到多个Tablet Server节点上。
算法流程
一个事务的所有 Write 在提交之前都会先缓存在 Client,然后在提交阶段一次性写入;Percolator 的事务提交是标准的两阶段提交,分为 Prewrite 和 Commit 。
Prewrite
- 从TO获取一个时间戳,作为事务的开始时间。
- 给数据上锁,标记数据被当前事务占有。上锁失败则表示数据被其他事物占有,当前事物失败。
上锁过程利用了Primary-Secondary机制,选择一个 Write 作为 primary,其它 Write 则是 secondary。Secondary的锁记录指向Primary。

显然,Prewrite阶段的数据对其他事务均不可见。
Commit
- 尝试对Prewrite中的数据进行Commit。Commit的时候先对Primary记录进行Commit,Primary记录的提交时间将作为整个事务的提交时间。首先对记录的锁记录进行检测,如果锁不存在,则表示Prewrite阶段的锁被其他事物清理,则事物执行失败。如果存在,则写记录中的write列,表示数据对系统可见。
异步网络之中,单节点故障,网络延迟很常见。算法需要在发现这些故障的时候,清理掉这些锁记录,避免死锁。所以,在Commit阶段,如果锁不存在,则表示事务的参与者发生了问题当前事务需要被清理。
- 提交成功之后对锁记录进行清理。显然,锁清理也是可以异步的。
这些设计使得算法去除了中心化Coordinator的依赖。因为过去需要依赖这个中心服务来维护事务各个参与者的信息。而在本算法中,利用Primary-Secondary二级锁以及Write列就可以实现。Write列表示数据对外的可见性以及数据版本链条。Lock列表示数据被事务持有。Primary-Secondary记录了参与者的逻辑从属关系。这样的设计使得Primary记录的提交变成了整个事务的提交点。一但Primary被提交,所有的Secondary记录可以通过检查对应Primary记录的Write列来进行异步提交。
Snapshot Isolation
两阶段提交解决的是事务的原子性。在此基础上,Percolator还提供了Snapshot Isolation的隔离性。简而言之,Snapshot Isolation要求提交的事务不能导致数据冲突,事务的读操作满足Snapshot Read。利用事务开始时间以及Primary记录的提交时间,可以维护一个事务之间的全序关系,这些问题自然就可以解决了。
异步网络的死锁问题
之前提到,异步网络之中,单节点故障,网络延迟很常见。算法需要在发现这些故障的时候,清理掉这些锁记录,避免死锁。故障检测的策略可以很简单,比如超时,故障会导致当前事务失败;节点故障又恢复正常,当时的事务已经失败,则此时需要对节点上相关锁记录进行清理。锁的清理可以异步化,比如在Prewrite上锁时,当发现记录Lock列非空,则去检测其Primary锁是否为空,Primary非空,则表示这个事务为完成,可以清理;为空则表示事务提交,则去找到事务提交时间,并把数据提交,再清理锁记录(RollForward)。
通知机制
通知机制对于异步系统的状态观测和联动很重要。但不是本文重点。
Percolator在TiDB上的使用
基于我们上文的分析,我们可以得出这样的结论:Percolator是一种优化过的2PC分布式事务实现,实现的基础是支持单机事务的存储引擎。
让我们来简单看看TiDB的的基于Percolator算法实现分布式事务。
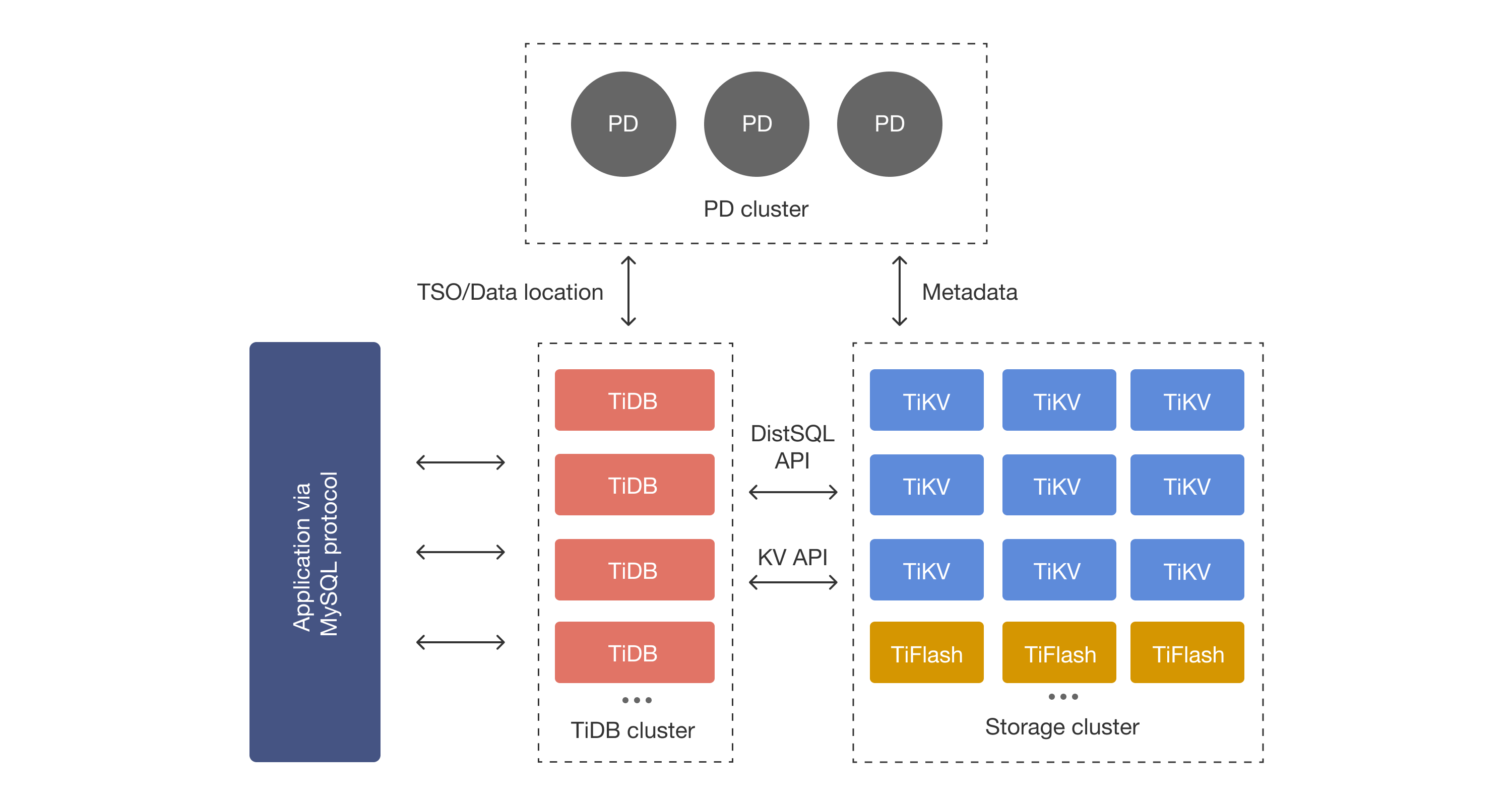
TiDB和TiKV架构如上。TiDB关系表里的数据最终都被映射到了TiKV中的KV中。TiKV是一个基于Raft+RocksDB的分布式KV。RocksDB是一个支持事务操作的KV。
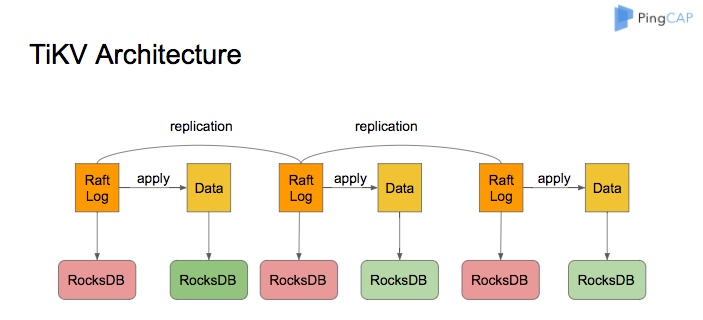
所以TiDB的事务的执行路径可以是这样:对关系表的事务操作转为对一组KV的事务操作,再基于Percolator去执行,以此实现关系表的事务操作。
当然不可能提供和单机TP数据库一样的事务语义和性能保证。但Share Nothing架构也有自己的优点,所以这个也许并不重要。
参考
文章作者 NoneBack
上次更新 2023-09-28
许可协议 true