MIT6.824-MapReduce
大三上学期课程有点硬核,一直没时间去继续6.824的学习,于是学习进度一直停在了Lab 1。寒假时间稍微充裕了点,于是打算继续推进。之后的每一个论文或者实验都会记录在文章中。
本文Distributed System学习笔记的第一章。
论文相关
论文最核心的内容是提出的MapReduce分布式计算模型,以及实现Distributed MapReduce System的思路,包括Master数据结构,容错以及一些refinement等内容。
MapReduce计算模型
模型接受一系列的键值对作为输入,并输出一系列键值对作为结果。用户通过设计Map和Reduce函数来使用MapReduce System
- Map:接受输入数据,生成一组中间键值对
- Reduce:接受中间键值对作为输入,将所有相同key的数据合并并作为结果输出。
|
|
MapReduce执行过程
Distrubuted MapReduce System采用主从的设计,在MapReduce计算过程中,一般有一个Master,以及若干个Worker。
- Master:负责Map以及Reduce任务的创建、分配、调度等
- Worker:负责执行Map以及Reduce任务
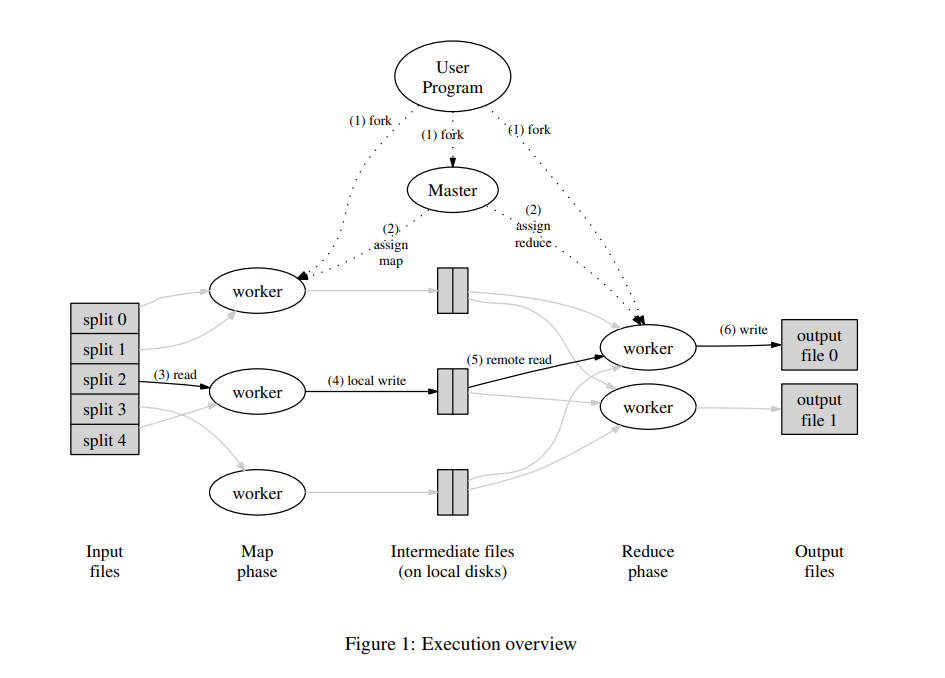
更详细的描述为:
1.MapReduce的整个执行过程包含M个Map Task 和R个Reduce Task,分为两个执行阶段Map Phase 和Reduce Phase。
2.输入的文件被拆分为M个split,计算进入Map Phase阶段,Master分配Map Task给空闲Worker。分配了Task的Worker读取对应的split data,执行Task。直到所有的Map Task都完成,Map Phase结束。利用Partition函数(一般为hash(key) mod R)得到R组中间键值对,保存在文件中,并将文件路径告知Master,以便Reduce Task的操作。
3.计算进入Reduce Phase阶段,Master分配Reduce Task,每个Worker读取对应的中间键值对文件,执行Task。所有Reduce执行完成后,计算完成。结果保存到结果文件中。
MapReduce 容错机制
由于 Google MapReduce 很大程度上利用了由 Google File System 提供的分布式原子文件读写操作,所以 MapReduce 集群的容错机制实现相比之下便简洁很多,也主要集中在任务意外中断的恢复上。
Worker容错
在集群中,Master 会周期地向每一个 Worker 发送 Ping 信号。如果某个 Worker 在一段时间内没有响应,Master 就会认为这个 Worker 已经不可用。
任何分配给该 Worker 的 Map 任务,无论是正在运行还是已经完成,都需要由 Master 重新分配给其他 Worker,因为该 Worker 不可用也意味着存储在该 Worker 本地磁盘上的中间结果也不可用了。Master 也会将这次重试通知给所有 Reducer,没能从原本的 Mapper 上完整获取中间结果的 Reducer 便会开始从新的 Mapper 上获取数据。
如果有 Reduce 任务分配给该 Worker,Master 则会选取其中尚未完成的 Reduce 任务分配给其他 Worker。鉴于 Google MapReduce 的结果是存储在 Google File System 上的,已完成的 Reduce 任务的结果的可用性由 Google File System 提供,因此 MapReduce Master 只需要处理未完成的 Reduce 任务即可。
如果集群中有某个 Worker 花了特别长的时间来完成最后的几个 Map 或 Reduce 任务,整个 MapReduce 计算任务的耗时就会因此被拖长,这样的 Worker 也就成了落后者(Straggler)。
MapReduce 在整个计算完成到一定程度时就会将剩余的任务进行备份,即同时将其分配给其他空闲 Worker 来执行,并在其中一个 Worker 完成后将该任务视作已完成。
Master容错
整个 MapReduce 集群中只会有一个 Master 结点,因此 Master 失效的情况并不多见。
Master 结点在运行时会周期性地将集群的当前状态作为保存点(Checkpoint)写入到磁盘中。Master 进程终止后,重新启动的 Master 进程即可利用存储在磁盘中的数据恢复到上一次保存点的状态。
Refinement
Partition Function
于Map Phase阶段使用,将中间键值对按照规则分配到R个文件中保存
Combiner
在某些情形下,用户所定义的 Map 任务可能会产生大量重复的中间结果键,Combiner 函数以对中间结果进行局部合并,减少 Mapper 和 Reducer 间需要传输的数据量。
实验相关
实验内容主要是设计实现Master和Worker,补全Simple MapReduce System的主要功能。
实验中通过Rpc调用实现单Master以及多Worker的模型,通过Go Plugin运行Map和Reduce函数组成的不同应用。
Master&Worker功能
Master
- 任务的创建,调度等
- Worker的注册,为其分配Task
- 接受Worker当前的运行状态
- 监听Task运行状态
worker
- 在Master中注册
- 获取任务并处理
- 报告运行状态
注:Master通过Rpc提供相应功能给Worker调用
主要数据结构
数据结构的设计是主要的工作,良好的设计结构有助于功能的实现。此处之展示数据结构相关代码,具体的功能实现见GitHub
Master
Worker
Task & TaskContext
Rpc Args & Reply
|
|
Constant & Type
运行与测试
运行
测试
优化
这些优化是在我完成实验之后,回顾自己代码时想到的可以优化的一些设计。
热点问题
这里的热点问题是,可能会有一个热点数据频繁的出现在数据集中。Map阶段的中间结果值K-V形式的,这样会导致在shuffle步骤的时候,一个Key频繁的出现,进而导致有个别机器的磁盘IO和网络IO被大量的占用。
这个问题的本质在于,MapReduce中的Shuffle在设计上是强依赖于数据的。
它的设计目的就是为了聚合中间结果数据以便Reduce阶段能够更好的进行处理。基于此,在数据极度分布不均的时候,自然会有热点问题。
实际上,问题本质是,大量的Key在Hash处理后被分配到以一个磁盘文件中,作为后续Reduce的输入。
同一个Key的Hash值理当是相同的,所以问题可以变形为:如何让相同的Key的Hash分桶到不一样机器中?
目前我想到的可行方式就是在Shuffle的Hash计算中,为Key添加随机salt,使得Hash的值不相同,减少哈希分桶到同一个机器的概率,进而解决热点问题。
容错问题
对于容错问题其实论文中已经有了一些解决方案。这个问题的场景是:Worker节点的机器突然Crash,并在重启之后重新连接。Master观测到Worker的Crash并将其任务重新分配给其他节点执行,这是Worker节点重新连接,之前的执行还在继续,双方都执行,可能导致生成两份结果文件。
这里的潜在问题是,这两份文件可能会导致结果出现错误。同时,重新连接的Worker继续执行原有的任务,浪费CPU,IO资源。
基于此,我们需要标明生成结果文件的新旧,只有最新的文件才能够被作为结果统计,这样就解决了文件冲突;同时,为Worker节点添加一个Rpc接口,使得其重新连接的时候,Master可以调用以清除原有任务。
长尾问题
长尾问题,就是指某个Task执行时间长,导致MapReduce无法迅速完成。其实本质上就是热点问题和Worker的Crash处理问题,可以参考上述博客。
参考
MapReduce: Simplified Data Processing on Large Clusters