MIT6.824 AuroraDB
这篇文章介绍了AWS的数据库产品Aurora的设计考虑,包括存算分离、一写多读、基于Quorum的NRW一致性协议等。同时,文章也提到了PolarDB参考Aurora进行设计,但在网络瓶颈和系统调用方面有所不同。
Aurora是AWS提供的一种数据库产品,主要面向OLTP的业务场景。
设计上,我觉得有这些值得参考的地方:
- Aurora设计的前提是,在数据库上云之后,得益于云基础设施的发展,数据库最大的瓶颈从计算和存储变成了网络, 这是AWS在设计Aurora的时候一个很重要的前提。基于此前提,Aurora重提Log is Database的论调,只将RedoLog下推至存储层。
- 存算分离。数据库存储层对接分布式存储底座,通过存储底座提供良好的可靠性和安全性保证。计算和存储层可以独立拓展。同时,存储底座对上层提供的单一数据视图,使得一些核心功能和运维操作效率得到很好的提升(比如备份,数据恢复,HA等)
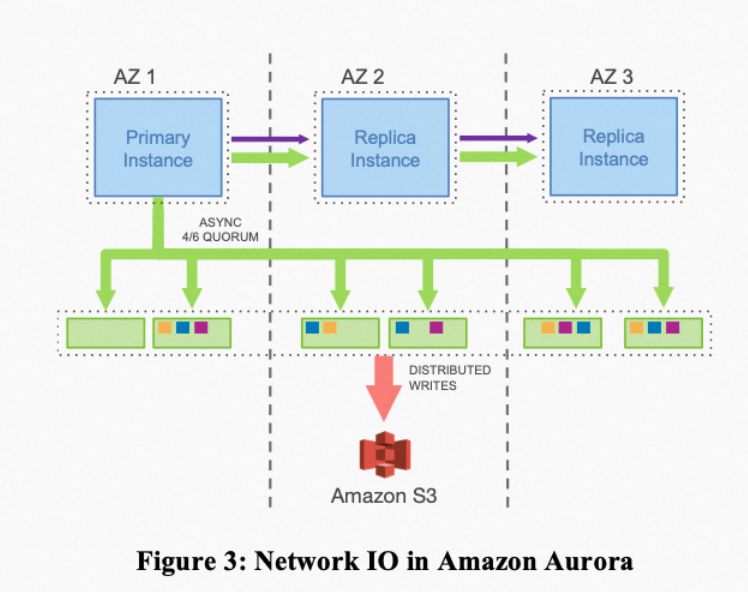
- 一些有意思的可靠性保证。比如基于Quorum的NRW一致性协议,存储节点读写都需要多数派的投票。保证双AZ级别的容错;用分片存储减少故障处理时间,以此提升SLA。多数读只发生在数据库恢复的时候,此时数据库需要恢复当前的状态。
- 一写多读。不同于ShareNothing架构的NewSQL产品,Aurora只提供了单个写节点。数据一致性保证也因此变得简单,因为单写节点可以通过RedoLog LSN作为逻辑时钟,以此维护数据更新操作的偏序关系,只需要把RedoLog下推至所有节点,并基于此顺序对这些操作Apply就可以保证数据的一致性。
- 事务的实现。由于存储底座对上层提供的单一文件视图,所以对与Aurora来说,其事务的实现几乎与单机事务算法相同,并能提供相同的事务语义。NewSQL的事务一般是基于2PC的分布式事务实现。
- 后台加速前台处理。类似LevelDB的思路,尽可能将存储节点的一些操作异步化(比如日志Apply),提升前台用户感知性能。这些异步的操作通过维护各种xxLSN来记录当前节点的后台处理进度,比如VLSN,commit-LSN等等
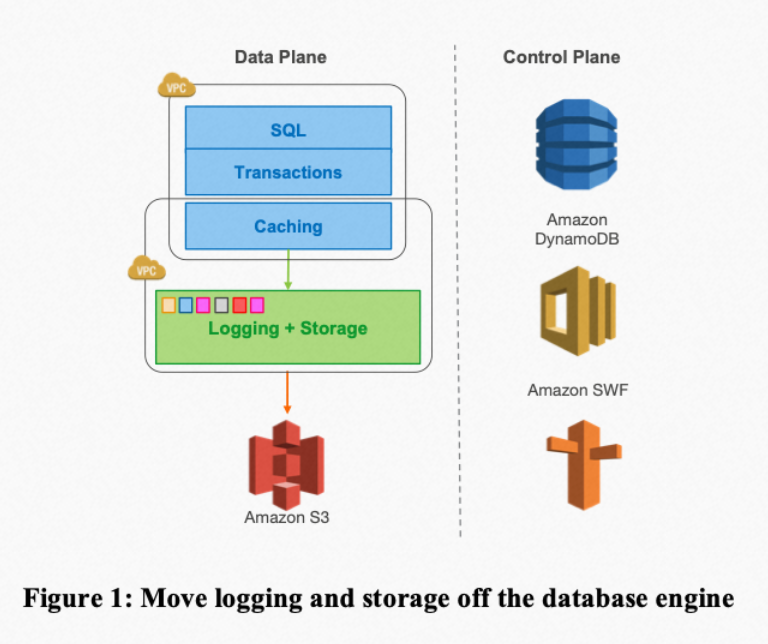
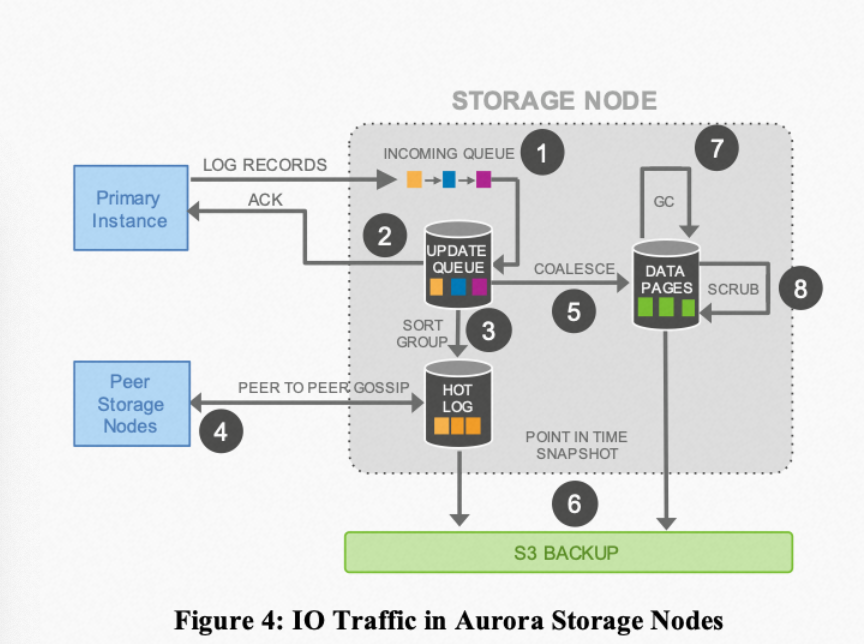
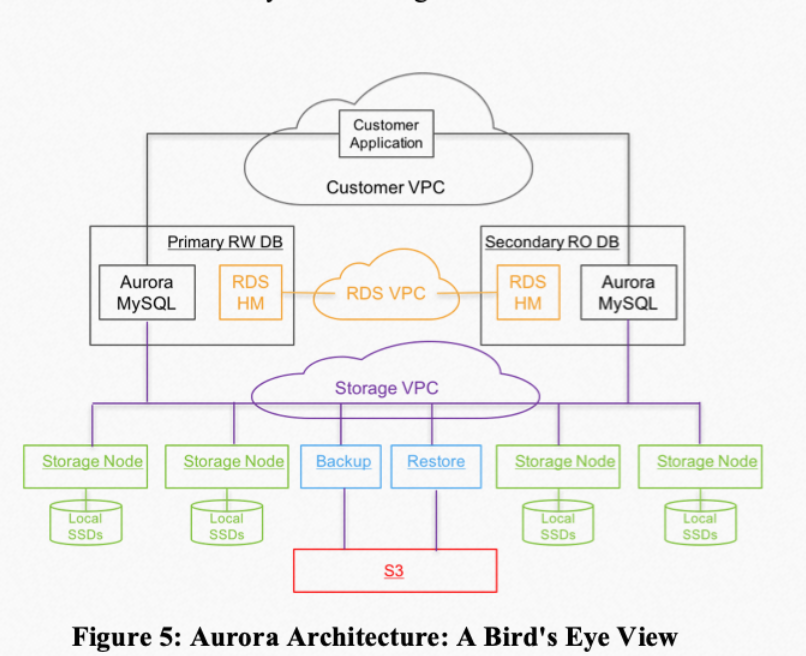
有趣的是,PolarDB虽然是参考Aurora进行的设计,但它的架构设计认为网络并非瓶颈,而是经过OS的各种系统调用拖慢了整体速度。在彼时阿里云存储底座并不稳定的条件下,所以才有了它架构中的PolarStore,用各种硬件以及FUSE等存储技术越过或者优化系统调用,而如今盘古在稳定性和性能上都做的很不错的情况下,弱化PolarStore这个组件也成为了正常的选择。我认为说的不无道理。
另外,为什么他们选择用NWR而不是用Raft之类的一致性协议?目前看上去,NWR在网络上,一次请求的网络比Raft少一轮,可能是这个原因
参考
https://zhuanlan.zhihu.com/p/319806107