LevelDB Write
LevelDB源码阅读笔记第二章,有关LevelDB的Write流程。本文并不是step by step的源码阅读教程,而是仅仅作为我的学习笔记,简单记录我的问题与思考。
主流程
LevelDB主要的写入逻辑其实比较简单。首先将写入操作封装到WriteBatch中,之后再执行写入。
WriteBatch
WriteBatch是对一组更新操作的封装,这一组操作会原子性的应用到状态机上。使用一块内存将用户的更新操作保存。
InMemory Format:
| seq_num: 8 bytes | count: 4 bytes | list of records{ type + key + value}
|
|
写入流程
写入操作主要有四步:
初始化Writer
Writer实际上就是一次写入操作需要的全部信息。
Writer调度
LevelDB的写入其实是一种多生产者单消费者的模式,多线程生产Writer,单线程消费Writer。每个Writer由一个线程产生,但可以被多个线程消费。 在LevelDB内部维护了一个Writer队列,每个线程的写入删除等更新操作会先将Writer追加到队列末尾,并用锁保证队列的数据安全。Writer被放入队列之后会进入等待,直到出现在队列头部(被调度)或者已完成(被其他线程处理)才会被唤醒。
在消费Writer, 执行具体的更新操作时,LevelDB通过将同类型(根据sync类型)的Writer合并来优化写入任务。
Writers Batches 写入
-
首先
MakeRoomForWrite确保memtable有足够的空间以及WAL保证写入成功。如果当前的memtable有空间则复用,如果空间不足,则新建memtable和WAL,并将原来的memtable转为immemtable,等待触发compaction(minor compaction 是串行的)。 -
除此之外,函数还会判断L0文件的数量,通过配置以及触发器判断是否需要对写入速率进行限制。其中主要包含两个配置:
- Slowdown Trigger。触发是会让写入线程Sleep,以减缓写入的速度,使得compaction任务得以处理;同时,以此限制Level 0 文件的数量,保证读效率。
- StopWritesTrigger。停止写入线程。
-
BuildBatchGroup则会将队列从头部开始同类型的Writer任务中需要写入的batches合并,只得到一个batch。 -
之后则是将合并之后的Batch先写WAL,再写memtable中。
WAL
WAL文件被拆分为Blocks, Blocks由Record组成。格式如下图: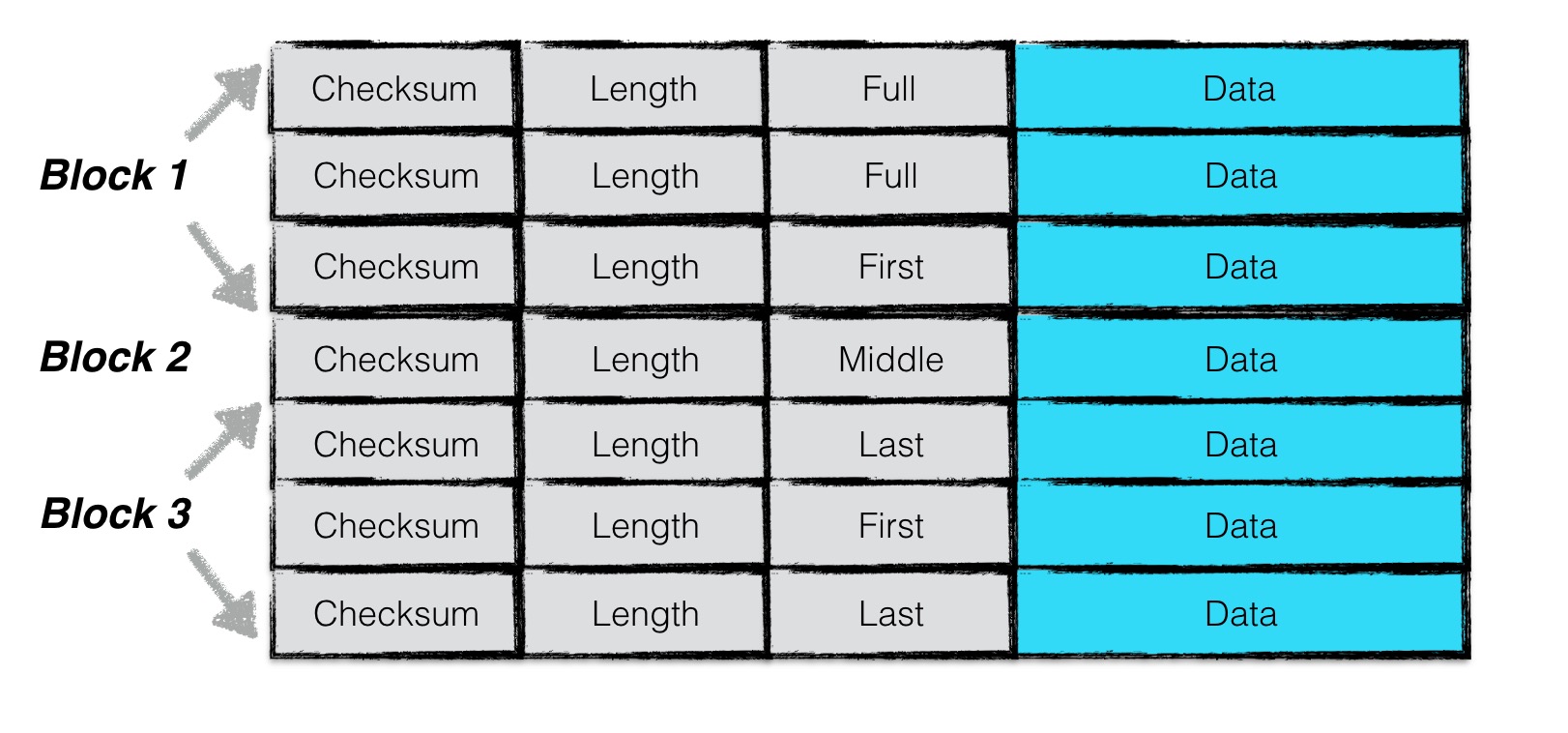
WAL Record Encoding
| Header{ checksum(4 bytes) + len(2 bytes) + type(1 bytes)} | Data |
其中Record主要有五类:Zero,Full,First,Middle,Last。其中Zero是预留给预分配文件。由于有个KV可能长度过长,需要由若干个Chunk记录,于是有了其他四种类型。
写入的流程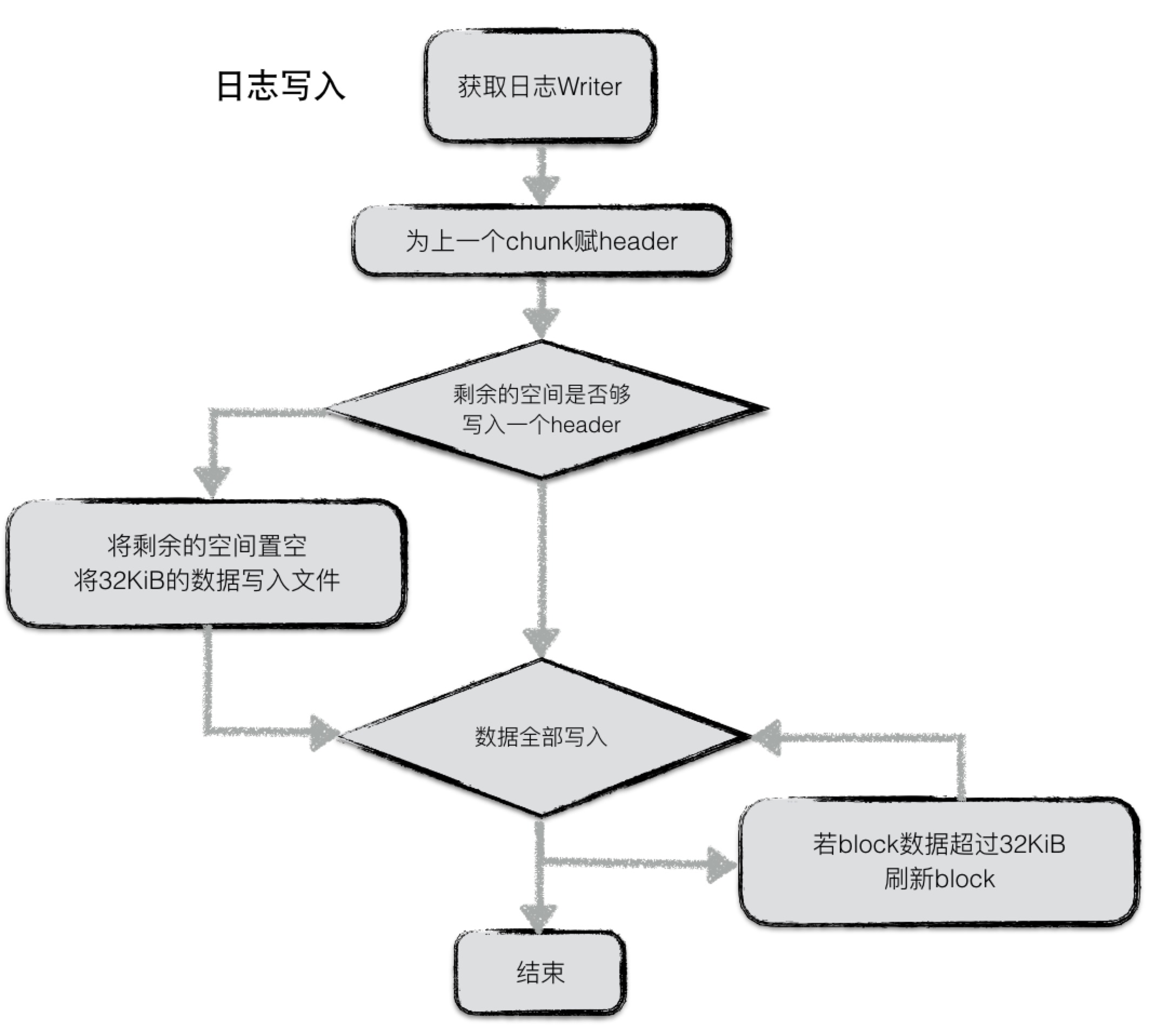
memtable
memtable的核心设计有两个:跳表以及KV在跳表中的编码。跳表保证了插入数据的有序性,具体的实现思路可以参考我的另一篇博客。
memtable的Key的编码之后的Key称之为Internal Key,其编码为| Original Key(varstring) + seq num(7 by) + type(1 byte) | 
SeqNum 是在每次更新操作时生成的一个递增的序号,作为逻辑时钟标记操作的新旧。基于SeqNum可以实现基于快照(版本号)的读取。