Kylin概述
之前就想着能做一个有意思的毕设,奈何周围都没有合适的老师。之前在学院启动选题之前找好了一个感觉不错的老师,但没想到最后把我鸽了。不过之前老师的方向也并不是那么感兴趣,于是也就作罢。 最近学院的毕设流程启动了,也在选题里看到了感兴趣的题目,于是便联系老师接了下来。
我选的题目是 《基于差分隐私的数据库查询算法的设计与实现》,方向是Differential Privacy + OLAP,具体一点就是为Kylin添加Differential Privacy的Feature。
总的来说就是如此,至于细节,也许在之后的博客中会写到。这是此系列博客的第一篇。
简介
Kylin是一种分布式的OLAP数据仓库,基于Hbase和Parquet等列存数据库以及Hadoop和Spark等运算调度框架,支持超大规模数据的多维分析。
它采用cube预计算的方法,把前台的实时查询变成了查询预计算结果,利用闲时的计算资源以及存储空间换取查询时间的优化,能极大的减少查询数据的时间。
背景
在Kylin之前,一般使用Hadoop来对大规模数据进行批处理,并将结果存储在Hbase等列式存储中。其中OLAP相关的技术便是大数据并行处理和列式存储。
-
大规模并行处理:实际上可以调用多台机其来并行处理计算任务,本质上是利用线性增长的计算资源来换取计算时间的线性下降。
-
列式存储:将记录按照列来存储。这方面主要是和OLAP的查询有关的,OLAP一般是对数据做统计等计算,一般都是同类型的列数据。列式存储使得查询时可以只访问需要的列并且可以充分利用顺序IO,提高性能。
以上两个技术使得Hadoop等平台上对于大数据的SQL查询达到了分钟级。但实际上,分钟级别的SQL查询依旧没法满足交互式分析的需要,效率依旧低下。
其中本质的原因在于,无论是并行计算或者是列式存储,都没有改变查询本身的时间复杂度,没有改变查询时间和数据量的线性增长关系。于是只能通过增加计算资源和利用局部性原理来对查询进行优化,这两种方法在数据量不断增长的情况下,都能明显的预见其成本上和理论上的瓶颈。
基于此,Kylin提出预计算策略,通过对不同的维度进行预计算生成多维cube(实际上就是一个数据表),后续的查询直接基于预计算的结果进行。经过预计算,物化视图的规模就只由维度的基数来决定,而不再随着数据量的增长呈线性增长。
这个策略本质上是利用空闲的计算资源以及额外的存储资源来换取查询时的响应速度,改变了查询时间与数据量之间的正比关系,从而提高效率。
核心概念
Apache Kylin 的工作原理本质上是MOLAP(Multidimensional Online Analytical Processing)Cube,多维立方体分析技术。
维度和度量
维度指用于审视,聚合数据的一种角度,一般是数据记录的某一个属性。度量是基于数据计算出来的具体数值。通过维度来聚合计算出度量值 $$D_1,D_2,D_3,… => S_1,S_2,…$$
cube理论
Data Cube,数据立方体,其主要涉及构建和查询两种操作,构建时对原始数据建立多维度索引以及预计算,以加速查询。
-
Cuboid: 指在某一维度组合下所计算出的数据
-
Cube Segment:Cube Segment是Cube的最小构建单位,一个Cube能被拆分为多个Cube Segment。
-
Cube增量构建:一般来说,增量构建Cube时是基于时间属性来触发的
-
Cube基数:Cube中所有维度的基数可以体现Cube的复杂度。复杂度高,Cube膨胀的概率会变高(IO,存储放大)。
架构设计
整个Kylin系统分为在线查询和离线构建两部分。
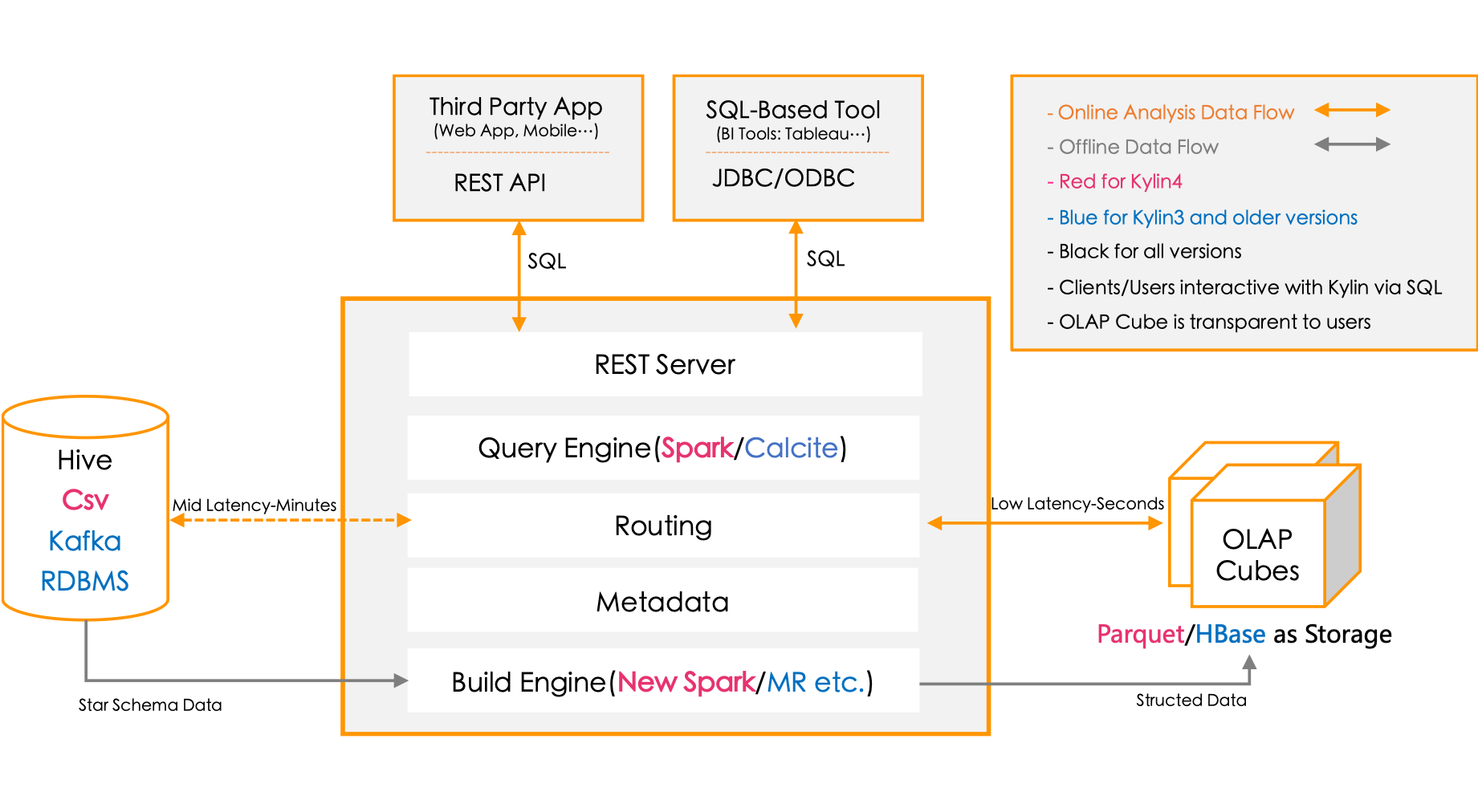
-
离线构建:主要有数据源,构建引擎,存储引擎三大抽象。从数据源拉取数据构建Cube在存储到列式存储引擎中。
-
在线查询:主要有接口层和查询引擎,对外部屏蔽Cube等底层概念。外部应用通过Rest API讲查询并转发给查询引擎,查询引擎查询与相关的数据返回结果。
总结
作为一个OLAP引擎,Kylin充分利用了并行计算,列式存储,预计算等优化技术提高其在线查询和离线构建性能,故而有如下几个明显的优缺点:
-
优点: 标准SQL接口,查询速度快,可拓展架构,BI系统友好
-
缺点:依赖的外部系统过多,运维困难;预计算与Cube构建导致的IO和存储放大;数据模型以及Cube基数的局限。
参考
Kylin权威指南