Java 多线程编程
昨天晚上再看梁勇的java进阶中的《多线程与并行程序设计》,今天想趁着写博客的机会,把我了解的记录下来。
Java 多线程编程
Java 给多线程编程提供了内置的支持。
- 一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
- 多线程是多任务的一种特别的形式,但多线程使用了更小的资源开销。
- 进程:一个进程包括由操作系统分配的内存空间,包含一个或多个线程。一个线程不能独立的存在,它必须是进程的一部分。一个进程一直运行,直到所有的非守护线程都结束运行后才能结束。
- 多线程能满足程序员编写高效率的程序来达到充分利用 CPU 的目的。
线程的状态
线程是一个动态执行的过程,它也有一个从产生到死亡的过程(状态)。
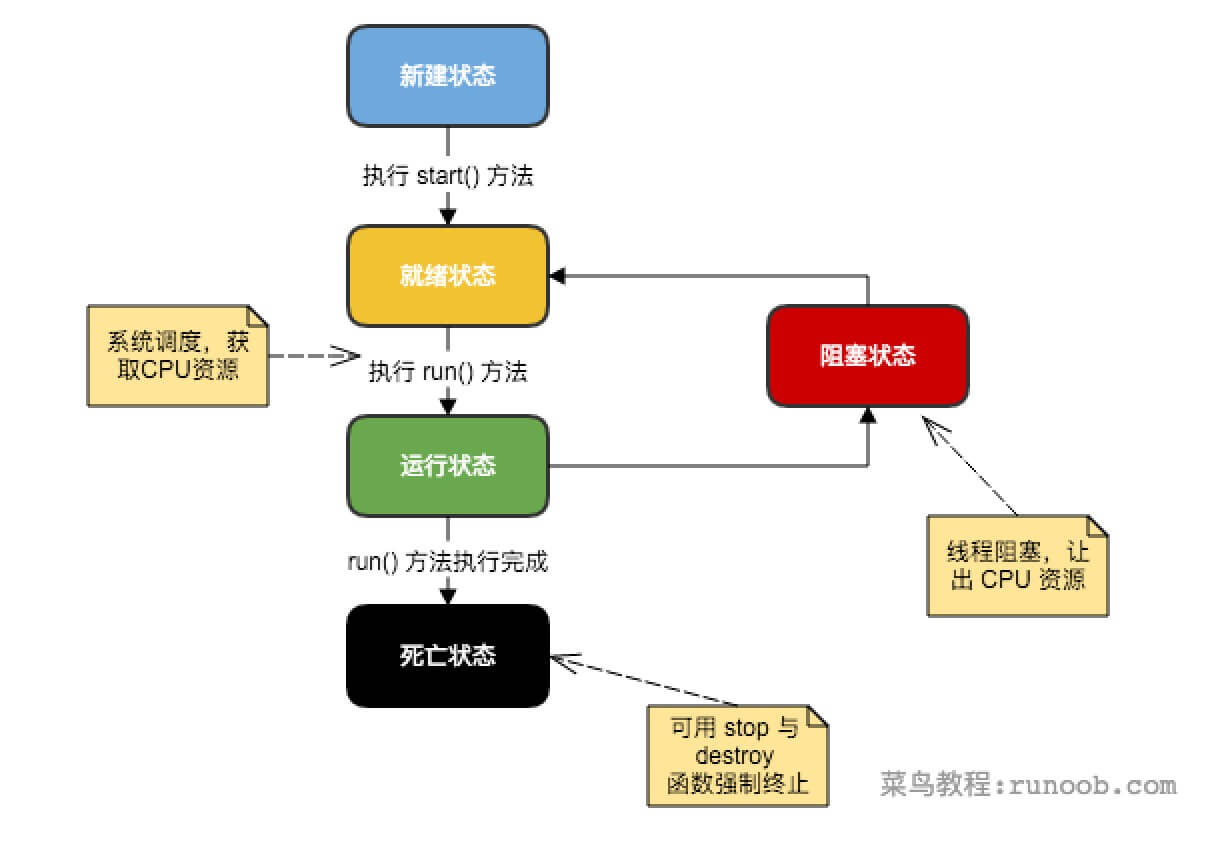
1.新建状态: 使用 new 关键字和 Thread 类或其子类建立一个线程对象后,该线程对象就处于新建状态。它保持这个状态直到程序 start() 这个线程。
2.就绪状态: 当线程对象调用了start()方法之后,该线程就进入就绪状态。就绪状态的线程处于就绪队列中,要等待JVM里线程调度器的调度。
3.运行状态: 如果就绪状态的线程获取 CPU 资源,就可以执行 run(),此时线程便处于运行状态。处于运行状态的线程最为复杂,它可以变为阻塞状态、就绪状态和死亡状态。
4.阻塞状态: 如果一个线程执行了sleep(睡眠)、suspend(挂起)等方法,失去所占用资源之后,该线程就从运行状态进入阻塞状态。在睡眠时间已到或获得设备资源后可以重新进入就绪状态。可以分为三种:
5.等待阻塞:运行状态中的线程执行 wait() 方法,使线程进入到等待阻塞状态。
6.同步阻塞:线程在获取 synchronized 同步锁失败(因为同步锁被其他线程占用)。
7.其他阻塞:通过调用线程的 sleep() 或 join() 发出了 I/O 请求时,线程就会进入到阻塞状态。当sleep() 状态超时,join() 等待线程终止或超时,或者 I/O 处理完毕,线程重新转入就绪状态。
8.死亡状态: 一个运行状态的线程完成任务或者其他终止条件发生时,该线程就切换到终止状态。
创建任务类与线程
- 任务就是一种对象,其必须实现Runable接口(Runable接口中只有run()函数),并且需要重写run(),以便线程创建时调用。
- 线程的创建是通过Thread类来构造的,Thread类中还包含了控制线程的方法。
一个线程的创建必须基于某个任务,即:
Thread中的其他方法
- yield():为其他线程临时让出cpu时间
- sleep():为线程设定休眠时间,以便其他线程的执行
sleep()可能抛出一个InterruptException异常,这是一个必检异常,java强制捕获,故而sleep函数必须在try代码块中。
线程的优先级
线程是有优先级的。java虚拟机总是优先执行优先级高的线程。若所有的优先级相同,则系统依照循环队列分配相同的cpu资源,即循环调度。
Thread类中的setPriority()可设定线优先级
线程池
对于大型任务数,如果必须为每个任务创建一个线程,那么启动新线程每个任务都可能限制吞吐量并导致性能不佳。 而使用线程池是理想的管理并发执行的任务数的方法。 Java 提供Exexutor接口来执行线程池中任务,用ExecutorService接口来管理和控制任务。执行器服务是执行器的子接口。 通过静态方法获得Executor对象,newFixedThreadPool(int)用于创建固定数目的线程池,newCachedThreadPool()则是自动创建线程。
demo:
|
|
线程池提供了一种更好的管理线程的方法。 线程池主要用来解决线程生命周期开销问题和资源不足问题。
- 线程池减少了在创建和销毁线程上所花的时间以及系统资源的开销。通过对多个任务重用线程,线程创建的开销就被分摊到了多个任务上了,而且由于在请求到达时线程已经存在,所以消除了线程创建所带来的延迟。这样,就可以立即为请求服务,使应用程序响应更快。另外,通过适当地调整线程池中的线程数目可以防止出现资源不足的情况。
- 线程池能够对线程进行方便的管理。比如使用ScheduledThreadPool来设置延迟N秒后执行任务,并且每隔M秒循环执行一次。
- 能控制线程池中的并发数。避免了因为大量的线程争夺CPU资源造成阻塞。
线程同步(Thread Synchronization)
如果同一个资源被多个线程同时访问,很可能会被破坏。如果两个任务以一种会引起冲突的方式访问一个公共资源,则称两者为竞争状态。若其没有竞争状态,则称其为线程安全的。
为避免竞争状态,应防止多个线程同事进入程序的某一特定部分,程序中这样的部分成为临界区。
解决竞争状态的方法便是使线程同步。
实现线程同步的方法
一个同步方法在执行前需要加锁。锁是一种实现资源排他的机制。对于实例方法,要给调用的对象加锁,对于静态对象,要给类加锁。
- synchronized关键字
此关键字可用与方法,也可用于表达式。
- 利用锁同步 可显式的使用锁和状态来同步线程。
一个锁是Lock接口的实例,其提供了加锁和释放锁的方法。 ReentrantLock是lock的具体体现,用于创建相互排斥的锁。
demo:
public void deposit(int amount) {
lock.lock(); // Acquire the lock
try {
int newBalance = balance + amount;
// This delay is deliberately added to magnify the
// data-corruption problem and make it easy to see.
Thread.sleep(5);
balance = newBalance;
}
catch (InterruptedException ex) {
}
finally {
lock.unlock(); // Release the lock
}
}
避免死锁
多个线程需要从几个共享对象上获取锁时,可能会导致死锁。
- 利用资源排序避免死锁
线程间的协作
可使用条件(Condition)实现线程的通信,指定其在某种条件下做什么。
**条件(Condition)**是通过Lock对象的newCondition()方法创建的对象。通过其await(),signal(),signall()实现线程的相互通信。
- await():让当前线程进入等待,直到条件发生(发出条件信号)
- signal()/signalAll():唤醒一个和所有线程
条件必须依赖与锁才可使用。无锁儿直接使用其方法会抛出IllegalMonitorStateExecption异常。
阻塞队列
java中为多线程提供了阻塞对列,同步可在对列中实现,所以不用在使用锁和条件。 它提供了两个附加操作:当队列中为空时,从队列中获取元素的操作将被阻塞;当队列满时,向队列中添加元素的操作将被阻塞。
阻塞队列常用于生产者和消费者的场景,生产者线程可以把生产结果存到阻塞队列中,而消费者线程把中间结果取出并在将来修改它们。
队列会自动平衡负载,如果生产者线程集运行的比消费者线程集慢,则消费者线程集在等待结果时就会阻塞;如果生产者线程集运行的快,那么它将等待消费者线程集赶上来。
作为BlockingQueue的使用者,我们再也不需要关心什么时候需要阻塞线程,什么时候需要唤醒线程,因为这一切BlockingQueue都给你一手包办了。
BlockingQueue的核心方法
1、放入数据
(1)put(E e):put方法用来向队尾存入元素,如果队列满,则等待。
(2)offer(E o, long timeout, TimeUnit unit):offer方法用来向队尾存入元素,如果队列满,则等待一定的时间,当时间期限达到时,如果还没有插入成功,则返回false;否则返回true;
2、获取数据
(1)take():take方法用来从队首取元素,如果队列为空,则等待;
(2)drainTo():一次性从BlockingQueue获取所有可用的数据对象(还可以指定获取数据的个数),通过该方法,可以提升获取数据效率;不需要多次分批加锁或释放锁。
(3)poll(time):取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,取不到时返回null;
(4)poll(long timeout, TimeUnit unit):poll方法用来从队首取元素,如果队列空,则等待一定的时间,当时间期限达到时,如果取到,则返回null;否则返回取得的元素;
一些状态
- 抛出异常:当队列满时,再向队列中插入元素,则会抛出IllegalStateException异常。当队列空时,再向队列中获取元素,则会抛出NoSuchElementException异常。
- 返回特殊值:当队列满时,向队列中添加元素,则返回false,否则返回true。当队列为空时,向队列中获取元素,则返回null,否则返回元素。
- 一直阻塞:当阻塞队列满时,如果生产者向队列中插入元素,则队列会一直阻塞当前线程,直到队列可用或响应中断退出。当阻塞队列为空时,如果消费者线程向阻塞队列中获取数据,则队列会一直阻塞当前线程,直到队列空闲或响应中断退出。
- 超时退出:当队列满时,如果生产线程向队列中添加元素,则队列会阻塞生产线程一段时间,超过指定的时间则退出返回false。当队列为空时,消费线程从队列中移除元素,则队列会阻塞一段时间,如果超过指定时间退出返回null。
并行编程
java可用Fork/Join框架实现并行编程 在此框架中,一个分解(Fork)可视为运行在一个线程上的独立任务。
将一个问题分解为多个不重叠的子问题(可独立解决),再合并子问题的解答以获得整体的解答。 框架使用ForkJoinTask类定义一个任务,在一个ForkJoinPool实例中执行任务。 ForkJoinTask是用于任务的基类,它是一个类似线程的实体,但比普通的线程要轻量级的多,因为巨量的任务可以被ForkJoinPool中的少数线程所执行。
demo:
import java.util.concurrent.RecursiveAction;
import java.util.concurrent.ForkJoinPool;
public class ParallelMergeSort {
public static void main(String[] args) {
final int SIZE = 7000000;
int[] list1 = new int[SIZE];
int[] list2 = new int[SIZE];
for (int i = 0; i < list1.length; i++)
list1[i] = list2[i] = (int)(Math.random() * 10000000);
long startTime = System.currentTimeMillis();
parallelMergeSort(list1); // Invoke parallel merge sort
long endTime = System.currentTimeMillis();
System.out.println("\nParallel time with "
+ Runtime.getRuntime().availableProcessors() +
" processors is " + (endTime - startTime) + " milliseconds");
startTime = System.currentTimeMillis();
MergeSort.mergeSort(list2); // MergeSort is in Listing 23.5
endTime = System.currentTimeMillis();
System.out.println("\nSequential time is " +
(endTime - startTime) + " milliseconds");
}
public static void parallelMergeSort(int[] list) {
RecursiveAction mainTask = new SortTask(list);
ForkJoinPool pool = new ForkJoinPool();
pool.invoke(mainTask);
}
private static class SortTask extends RecursiveAction {
private final int THRESHOLD = 500;
private int[] list;
SortTask(int[] list) {
this.list = list;
}
@Override
protected void compute() {
if (list.length < THRESHOLD)
java.util.Arrays.sort(list);
else {
// Obtain the first half
int[] firstHalf = new int[list.length / 2];
System.arraycopy(list, 0, firstHalf, 0, list.length / 2);
perform the task
sort a small list
split into two parts
// Obtain the second half
int secondHalfLength = list.length - list.length / 2;
int[] secondHalf = new int[secondHalfLength];
System.arraycopy(list, list.length / 2,
secondHalf, 0, secondHalfLength);
// Recursively sort the two halves
invokeAll(new SortTask(firstHalf),
new SortTask(secondHalf));
// Merge firstHalf with secondHalf into list
MergeSort.merge(firstHalf, secondHalf, list);
}
}
}
}