先从epoll说起。
epoll是Linux内核的可拓展IO事件通知机制,设计的目的是取代select和poll,是为了处理大量文件描述符而改进的poll,支持打开文件描述符上限是系统最大文件打开数目,性能优异。
使用
API
epoll相关的系统调用有三个
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
/** epoll_create
* 创建一个epoll句柄,返回错误码
* 使用之后需要被关闭,因为epfd也会消耗系统fd数量。
* size : 标识epfd监听fd的数量
*/
int epoll_create(int size);
/** epoll_ctl
* 添加epoll监控对象,epoll事件的注册函数,返回错误码
* epfd : epoll fd
* op : 操作类型
* EPOLL_CTL_ADD : 注册新的fd到epfd中
* EPOLL_CTL_MOD : 修改已经注册的fd的监听事件
* EPOLL_CTL_DEL : 从epfd中删除一个fd
* fd : 需要监听的fd
* event : 需要监听的事件
* EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
* EPOLLOUT:表示对应的文件描述符可以写;
* EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
* EPOLLERR:表示对应的文件描述符发生错误;
* EPOLLHUP:表示对应的文件描述符被挂断;
* EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
* EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
*/
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
/** epoll_wait
* 收集已经触发了的事件,返回触发事件的数目,0代表超时
* epfd : epoll fd
* events : epoll将触发的事件赋值到events数组中
* maxevent : 告知kernel events数组的大小,不得大于epoll_create 中的 size
* timeout : 等待超时时间,0,立即返回,-1 一直阻塞,> 0 等待对应时间
*/
int epoll_wait(int epfd, struct epill_event* events,int timeout);
|
处理过程
epoll_create
当一个进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
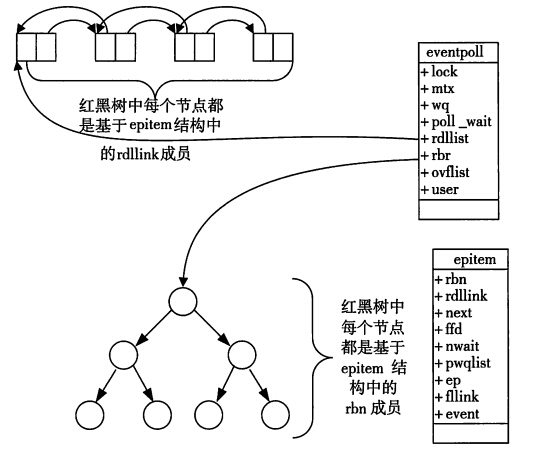
struct eventpoll {
/* Protect the this structure access */
spinlock_t lock;
/*
* This mutex is used to ensure that files are not removed
* while epoll is using them. This is held during the event
* collection loop, the file cleanup path, the epoll file exit
* code and the ctl operations.
*/
struct mutex mtx;
/* Wait queue used by sys_epoll_wait() */
/* 阻塞在epoll_wait()当前epoll实例的用户被链接到这个等待队列 */
wait_queue_head_t wq;
/* Wait queue used by file->poll() */
/* epoll文件也可以被epoll_wait() */
wait_queue_head_t poll_wait;
/* List of ready file descriptors */
/* 已经ready的epitem的链表 */
struct list_head rdllist;
/* RB tree root used to store monitored fd structs */
struct rb_root rbr;
/*
* This is a single linked list that chains all the "struct epitem" that
* happened while transfering ready events to userspace w/out
* holding ->lock.
*/
/* 见ep_poll_callback()以及ep_scan_ready_list()中的注释 */
struct epitem *ovflist;
/* The user that created the eventpoll descriptor */
/* 创建当前epoll实例的用户 */
struct user_struct *user;
struct file *file;
/* used to optimize loop detection check */
int visited;
struct list_head visited_list_link;//双向链表中保存着将要通过epoll_wait返回给用户的、满足条件的事件
};
|
在epoll_create中,epoll向内核注册了一个红黑树,用于存储上述的被监控socket。当你调用epoll_create时,就会在这个rb tree里创建一个file结点,通过rb tree查询对应的socket fd。
同时,它还会创建一个双向链表用于存储准备就绪的事件。
epoll_ctl
在epoll中,对于每一个事件都会建立一个epitem结构体:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
/*
* Each file descriptor added to the eventpoll interface will
* have an entry of this type linked to the "rbr" RB tree.
*/
struct epitem {
/* RB tree node used to link this structure to the eventpoll RB tree */
/* eventpoll内部的红黑树的挂载点 */
struct rb_node rbn;
/* List header used to link this structure to the eventpoll ready list */
/* 所有已经ready的epitem都会被挂载到eventpoll的rdllist中 */
struct list_head rdllink;
/*
* Works together "struct eventpoll"->ovflist in keeping the
* single linked chain of items.
*/
/* 配合eventpoll->ovflist使用 */
struct epitem *next;
/* The file descriptor information this item refers to */
/*
* 作为evetnpoll内部的红黑树节点的key
*/
struct epoll_filefd ffd;
/* Number of active wait queue attached to poll operations */
/* 监听队列挂载数 */
/* 难道一个epitem还能同时挂载到多个监听队列? */
int nwait;
/* List containing poll wait queues */
/* 链接当前epitem对应的eppoll_entry结构 */
struct list_head pwqlist;
/* The "container" of this item */
/* 关联当前epitem所属的epollevent */
struct eventpoll *ep;
/* List header used to link this item to the "struct file" items list */
/* 与所监听的struct file进行链接 */
struct list_head fllink;
/* The structure that describe the interested events and the source fd */
/* 通过epoll_ctl从用户空间传过来的数据,表示当前epitem关心的events */
struct epoll_event event;
};
|
在调用epoll_ctl时,除了将socket fd注册到eventpoll的rb tree,它还会给内核中断处理程序注册一个回调函数。当这个fd的中断到了,就把它放入就绪链表中。当一个socket上有数据到了,内核在把网卡上的数据copy到内核中后就来把socket插入到准备就绪链表里了。
epoll_wait
当epoll_wait调用时,仅仅观察这个list链表里有没有数据即eptime项即可。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。
Epoll使用模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
for( ; ; )
{
nfds = epoll_wait(epfd,events,20,500);
for(i=0;i<nfds;++i)
{
if(events[i].data.fd==listenfd) //有新的连接
{
connfd = accept(listenfd,(sockaddr *)&clientaddr, &clilen); //accept这个连接
ev.data.fd=connfd;
ev.events=EPOLLIN|EPOLLET;
epoll_ctl(epfd,EPOLL_CTL_ADD,connfd,&ev); //将新的fd添加到epoll的监听队列中
}
else if( events[i].events&EPOLLIN ) //接收到数据,读socket
{
n = read(sockfd, line, MAXLINE)) < 0 //读
ev.data.ptr = md; //md为自定义类型,添加数据
ev.events=EPOLLOUT|EPOLLET;
epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev);//修改标识符,等待下一个循环时发送数据,异步处理的精髓
}
else if(events[i].events&EPOLLOUT) //有数据待发送,写socket
{
struct myepoll_data* md = (myepoll_data*)events[i].data.ptr; //取数据
sockfd = md->fd;
send( sockfd, md->ptr, strlen((char*)md->ptr), 0 ); //发送数据
ev.data.fd=sockfd;
ev.events=EPOLLIN|EPOLLET;
epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev); //修改标识符,等待下一个循环时接收数据
}
else
{
//其他的处理
}
}
}
|
阻塞IO、非阻塞IO、IO复用
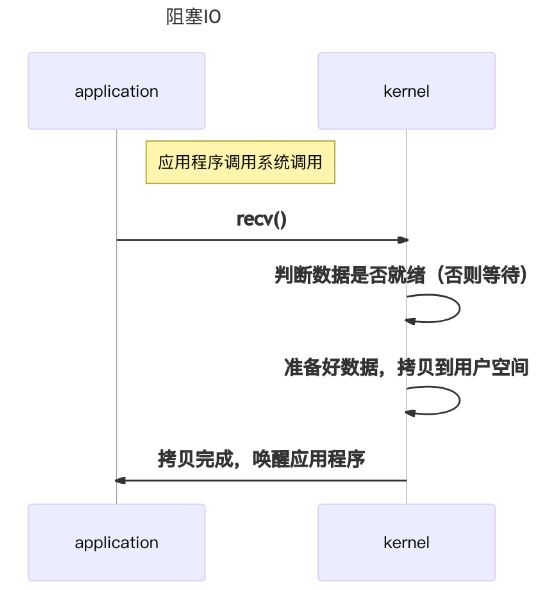
阻塞IO意味着线程在数据未到达时需要等待数据到达,阻塞的进程是不应当占用CPU的,此时需要让出CPU,调入新的task占用CPU。知道数据到达,再重新获取将这个task调入CPU执行。用户进程独立处理业务
1
2
3
|
printf("Calling recv(). \n");
ret = recv(socket, recv_buf, sizeof(recv_buf), 0);
printf("Had called recv(). \n");
|
基于此,当大量task出现读写请求时,大量的CPU上下文切换,task调度,效率可能会低下
非阻塞IO
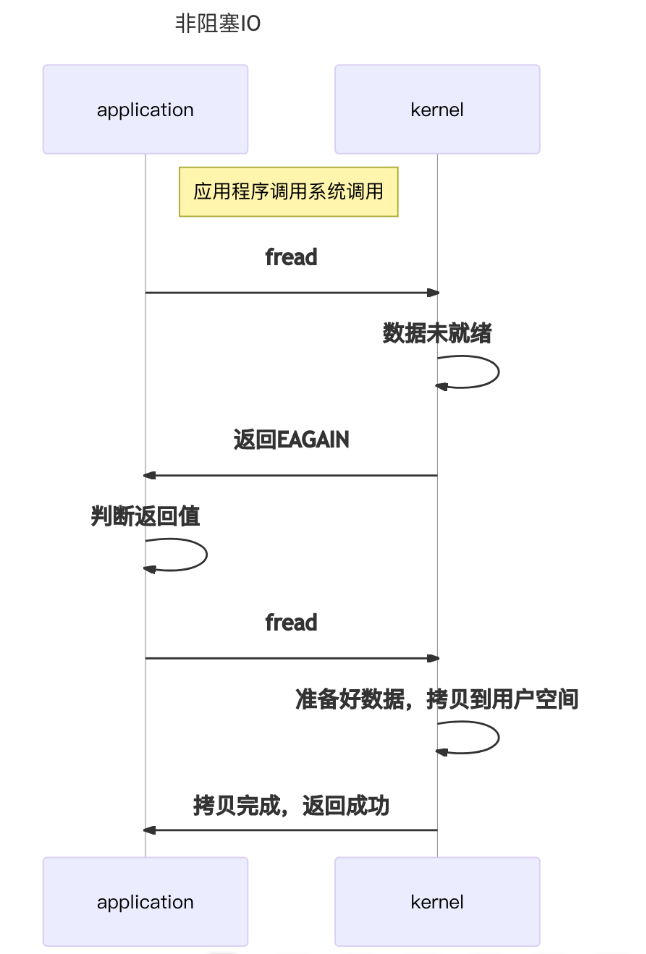
当用户线程发起一个IO操作后,并不需要等待,而是马上就得到了一个结果。如果结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送IO操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。
在非阻塞IO模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞IO不会交出CPU,而会一直占用CPU。
1
2
3
4
5
6
7
8
|
while(1)
{
printf("Calling recv(). \n");
ret = recv(socket, recv_buf, sizeof(recv_buf), 0);
if (EAGAIN == ret) {continue;}
else if(ret > -1) { break;}
printf("Had called recv(), retry.\n");
}
|
对于非阻塞IO就有一个非常严重的问题,在while循环中需要不断地去询问内核数据是否就绪,这样会导致CPU占用率非常高,因此一般情况下很少使用while循环这种方式来读取数据。
IO复用
阻塞IO的问题是,业务交由线程处理,阻塞导致大量的资源被占用;阻塞与恢复会可能会导致大量的上下文切换,效率低下;
非阻塞IO的问题是,在不使用监视器的情况下,依靠死循环完成一次 IO 操作。但是这样做的效率实在是太低了,完全没有实际意义;
实际上,task的运行是不可避免的,有数据需要处理,就需要CPU去执行。所以可以优化的点在于,如何减少运行处理业务的线程以减少上下文调度开销和等待线程资源占用,以及减少CPU无意义的空转。
IO复用的基本思想就是,在一个线程中管理监听多个fd事件,减少上下文切换;采用事件通知机制,减少CPU的空转;
由此衍生出的select,poll,epoll,不过此乃他话,姑且不论。
参考
Linux下的I/O复用与epoll详解
深入理解 epoll