Dynamo: Amazon’s Highly Available Key-value Store
一篇AWS的老文章,Dynamo到现在已经售卖了很久了,架构应该也早已不像论文中描述的这样。但文章入选了某年的sigmod best paper,依旧是有很多值得学习的地方。
设计
Dynamo是一种NoSQL产品,对外提供KV存储语义。在产品定义上强调Highly Available而非Consistency,所以在架构设计以及技术选型上和其他的产品还是有很多不同之处。
技术
在技术上,Dynamo其实有很多有问题的地方,比如NWR算法本身的一些。但考虑到Dynamo已经经过了很长时间的验证,也许这些问题已经被很好的解决了,只不过论文中语焉不详。所以暂且放下这些,挑一些来说一说。其中我认为值得拿出来说的主要有这几块:
数据的分区
一致性hash算法。传统的一致性hash算法使用hash ring来解决增减节点rehash范围大的问题,但比如数据倾斜,以及异构机器导致的性能倾斜这类问题是无法避免的。 Dynamo实践上,在原有hash ring上引入了虚拟节点,比较优雅的解决了这两个问题。
数据写入问题
一般存储系统会在写的同时保证一定的数据一致性,换取较低的读操作复杂度,代价上写性能降低(延迟等)。但Dynamo选择了另一条路线。
Dynamo的设计目标是提供一个高可用的KV Store,保证always writable,同时只保证最终的一致性。这样的目标使得Dynamo把解决数据冲突之类的操作放到了读操作中,以保证写永远不会被拒绝。
总的来说,问题有两个。一个是数据更新冲突问题,显然多client并发的读写同一个Key很容易遇到这样的问题,因为Dynamo只能提供最终一致性,Dynamo Ring 上多个节点的数据不一定一致。二是节点数据空洞的问题。因为Dynamo使用的是NMR这类的gossip算法,这类理论上会出现所有节点上都不包含完整数据集的情况,需要同步副本之间的数据。
前者使用版本时钟来标记数据版本,后续在读操作的时候进行读修复合并数据版本;后者有熵逆过程来处理,使用MerkleTree来快速检测副本之间的不一致性,以及最小化转移的数据量。
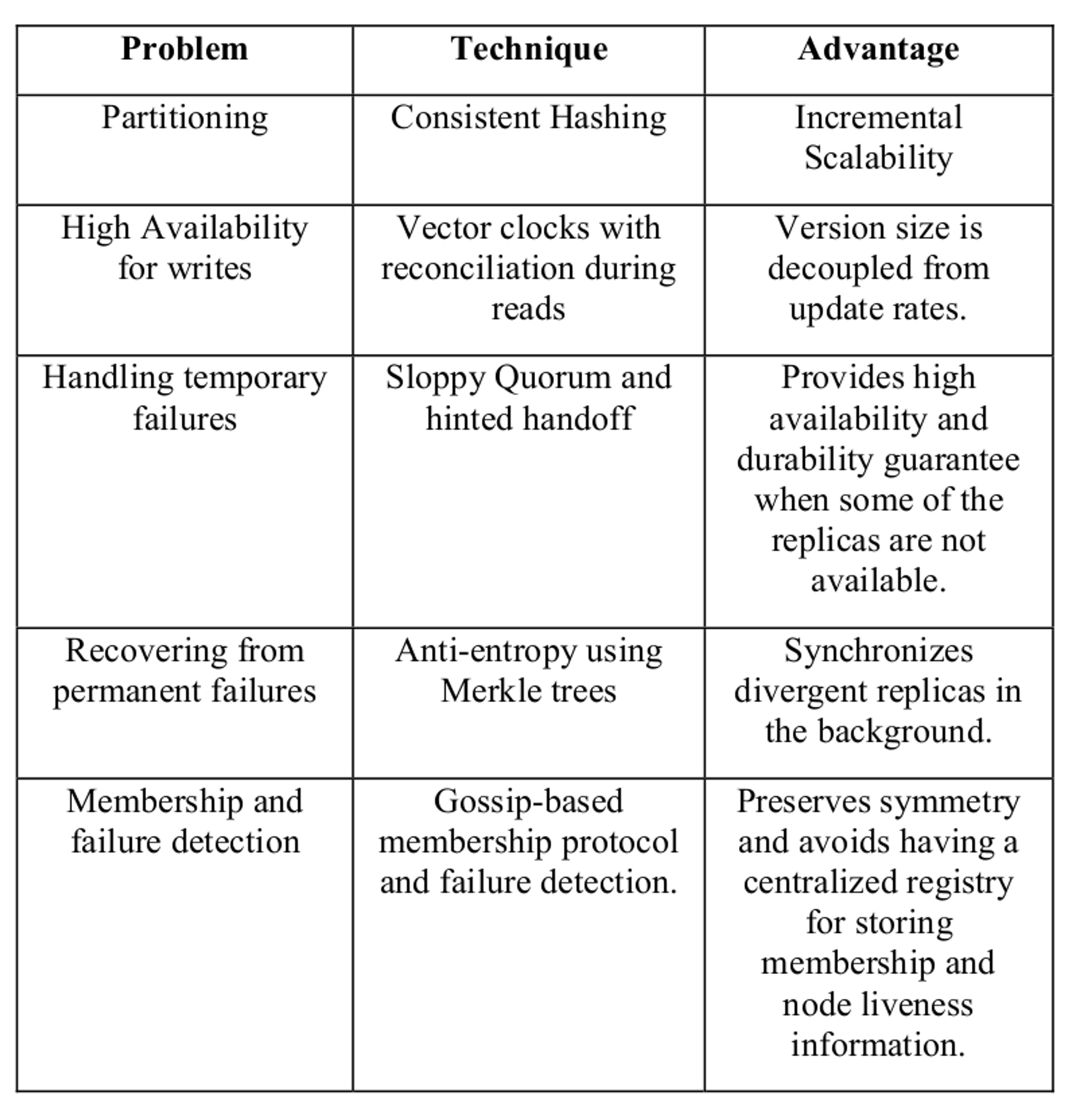 论文中的这个表格可以清楚的看出Dynamo设计开发需要考虑的方面以及在技术上的选择。剩下这些论文中感觉语焉不详,可以参考原文。
论文中的这个表格可以清楚的看出Dynamo设计开发需要考虑的方面以及在技术上的选择。剩下这些论文中感觉语焉不详,可以参考原文。
参考
文章作者 NoneBack
上次更新 2023-08-01
许可协议 true