Apache-Iceberg调研
- 一种用于大规模分析数据集的表格式。
- 一种对数据文件和元数据文件的组织规范。
- 一种介于存储和计算中间的schema语义抽象。
- netflix开发开源,旨在提升拓展性、可靠性、以及易用性。
背景
HIVE 上云遇到的一系列问题:
- 依赖List和Rename语义,无法使用更廉价的OSS代替HDFS。
- 可拓展性问题。Hive中的Schema信息集中存储于metastore中,可能会成为性能瓶颈
- 不安全操作、cbo不友好、etc
特性
- 支持安全高效的schema,partition变更和演进,self-define schema,hidden partition
抽象了自己的schema,不绑定任何计算引擎层面的schema;schema层面维护partition。partition和sort order 提供transformer函数,如 date(timestamp)
-
支持对象存储,对fs语义依赖少
-
ACID语义支持,读写并行,写操作串行化: 读写快照分离;乐观处理写并行冲突,重试保证写入
-
snapshot,支持数据回滚以及时间回溯,支持snapshot过期删除(默认不删除数据文件,但可以定制删除行为(related api doc))。通过对比snapshot差异可以实现增量读取。
-
查询优化友好,predict pushdown, data file statistics,目前好像不支持compaction, 可以在snapshot过期删除的删除无效文件(deleteWith)
-
抽象程度高,方便改造优化拓展。catalog,读写路径,文件格式,存储依赖 插件化。Iceberg的设计初衷是定义于一个标准、开发且通用的数据组织格式,同时屏蔽底层数据存储格式上的差异,向上提供统一的操作API,使得不同的引擎可以通过其提供的API接入。
-
其他:文件级别加密解密
生态
-
社区对OSS & Flink & Spark & Presto均有一定支持
- flink(detail):支持流式读写和增量读取(基于snapshot),upsert write(0.13.0-release-notes)
- presto: Iceberg connector
- Aliyun oss: # pr 3689
-
其他组件对接
- 对接下层存储:只依赖三种语义In-place write,Seekable reads,Deletes,支持AliOSS(# pr 3689)
- 对接其他文件格式:抽象程度高,目前支持avro,parquet,orc
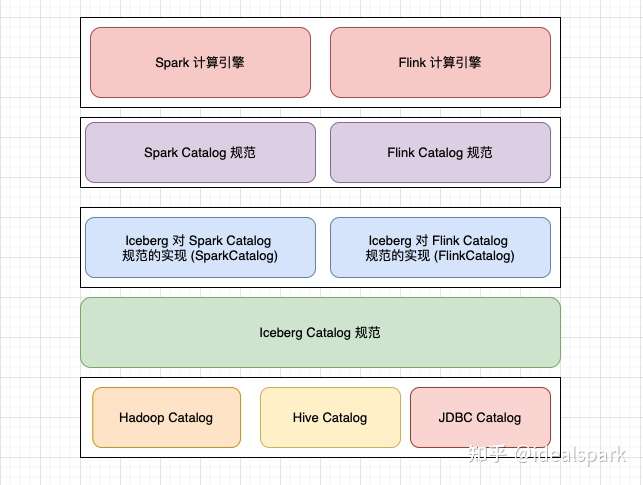
- Catalog:可定制化(Doc:Custom Catalog Implementation),目前支持JDBC,Hive metastore,hadoop等
- 对接计算层:提供原生 JAVA & Python API,抽象程度高,支持大多数计算引擎
-
社区开放中立,可以参与贡献,提高影响力
表规范
对数据文件和元数据文件的组织规范。

Case:Spark + IceBerg + Local FS
ice-berg 支持parquet,Avro,ORC 三种文件格式
|
|
DataFile
数据文件,列存,parquet,orc
有三种类型的Data File,data file,partition delete file,equality delete file(
Manifest File
索引数据文件,同时包含statistics, partition,
|
|
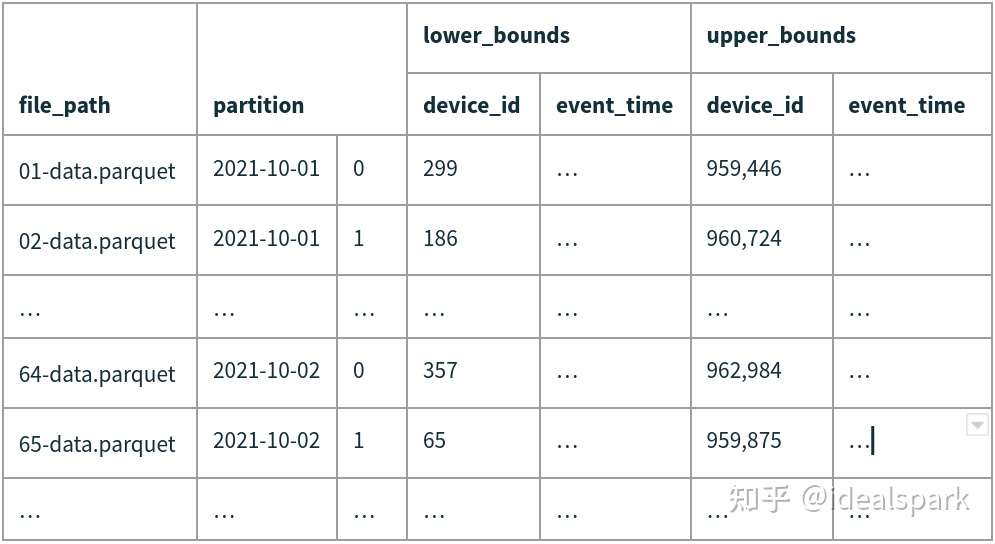
Snapshot
- 代表某个时刻Table的状态。通过Manifest List File保存。
- 每次对Table进行数据变更都会生成一个新的Snapshot。
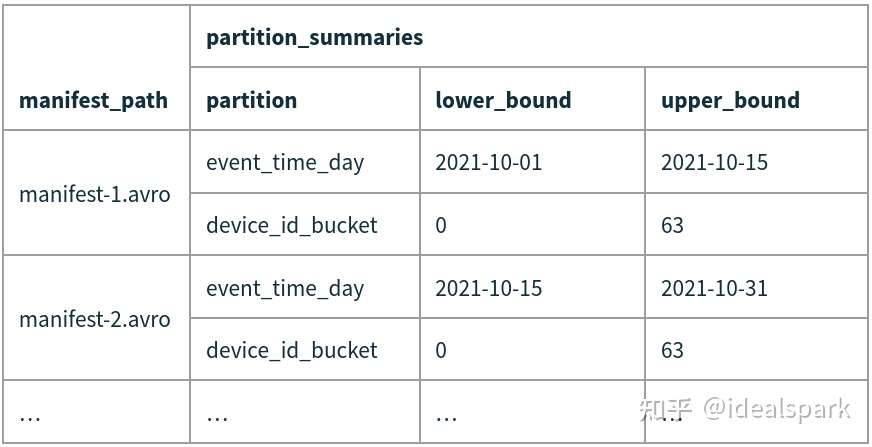
Manifest List File
- 包含了一个Snapshot包含的所有Manifest文件的信息,以及Partition stats和Data File Count。
- 一个Snapshot对应一个Manifest List File,每次提交一个Snapshot会生成一个manifest list file。
- 乐观并发处理,并发提交snapshot冲突时,后提交的请求会重试保证提交。
Each manifest list stores metadata about manifests, including partition stats and data file counts.
|
|
Metadata File
包含了表的所有状态。表状态变更的时候会生成一个新的metadata,并替换原有的metadata file,此过程保证原子性。
The table metadata file tracks the table schema, partitioning config, custom properties, and snapshots of the table contents
|
|
Catalog
记录最新的metadata file路径
特性
- ACID语义保证:原子性的表状态变更 + 基于快照读写
- 分区管理灵活:hidden partition,无感分区变更
- 支持增量读取:可以根据snapshot来增量读取每一次修改的数据
- 数据多版本:利好数据回滚
- 无副作用、安全的schema、partition变更
数据类型
不同数据格式的数据文件,对不同的Type会有不同定义
-
Nested Types
- struct:a tuple of typed values
- list:a collection of values with some element type
- map:a collection of key-value pairs with a key type and a value type.
-
Primitive Type
| Primitive type | Description | Requirements |
|---|---|---|
**boolean** |
True or false | |
**int** |
32-bit signed integers | Can promote to long |
**long** |
64-bit signed integers | |
**float** |
32-bit IEEE 754 floating point | Can promote to double |
**double** |
64-bit IEEE 754 floating point | |
**decimal(P,S)** |
Fixed-point decimal; precision P, scale S | Scale is fixed [1], precision must be 38 or less |
**date** |
Calendar date without timezone or time | |
**time** |
Time of day without date, timezone | Microsecond precision [2] |
**timestamp** |
Timestamp without timezone | Microsecond precision [2] |
**timestamptz** |
Timestamp with timezone | Stored as UTC [2] |
**string** |
Arbitrary-length character sequences | Encoded with UTF-8 [3] |
**uuid** |
Universally unique identifiers | Should use 16-byte fixed |
**fixed(L)** |
Fixed-length byte array of length L | |
**binary** |
Arbitrary-length byte array |
读取 & 写入路径
select:catalog -> manifest list file -> manifest file -> data file -> data group
insert:reverse(catalog -> manifest list file -> manifest file -> data file -> data group)
update:delete & insert, data file + partition delete file + equality delete file,
使用Patition delete file transaction 内同一行数据反复插入删除的语义问题
delete:row level delete
参考
Flink + Iceberg 全场景实时数仓的建设实践 Flink 中文社区