Linux中的Fork
这原本是大二时学习操作系统是写下的一篇博客,近几日对它稍微添加了一些COW的内容。
前言
最近最学习操作系统,在《operating system concept》的进程一章节中中有这样一段代码:
|
|
查阅了些资料,看了几回才稍微看懂一点fork()的用法,于是写下这篇博客记录一下。
fork()函数介绍
简介:建立一个新的进程
表头文件:
|
|
定义函数:
|
|
函数说明:
vfork()会产生一个新的子进程,其子进程会复制父进程的数据与堆栈空间,并继承父进程的用户代码,组代码,环境变量、已打开的文件代码、工作目录和资源限制等。Linux 使用copy-on-write(COW)技术,只有当其中一进程试图修改欲复制的空间时才会做真正的复制动作,由于这些继承的信息是复制而来,并非指相同的内存空间,因此子进程对这些变量的修改和父进程并不会同步。此外,子进程不会继承父进程的文件锁定和未处理的信号。注意,Linux不保证子进程会比父进程先执行或晚执行,因此编写程序时要留意 死锁或竞争条件的发生。
返回值:
如果vfork()成功则在父进程会返回新建立的子进程代码(PID),而在新建立的子进程中则返回0。如果vfork 失败则直接返回-1,失败原因存于errno中。
错误代码:
EAGAIN 内存不足。ENOMEM 内存不足,无法配置核心所需的数据结构空间。
函数使用分析
首先我们看看开头代码的运行结果:

Linux中进程是通过链表进行组织的,所以本文中使用 ParentProcess->ChildrenProcess的格式展示。
下面开始上面分析结果:
-
首先,fork()函数会调用两次,第一次在父进程中返回,返回子进程的pid(一般大于零),第二次是在子进程中调用,返回0;当fork()失败时,返回一个负数。
-
父进程开使执行,调用fork(),返回一个子进程pid(>0),执行打印Parent pid 25974,然后等待子进程。
-
子进程在父进程调用fork()后开始执行,在子进程中fork()返回0(并不是实际意义上的调用之后返回,而是在子进程中直接返回了0,在后面在解释),执行父进程fork()后面的语句,即execlp("/bin/ls",“ls”,NULL),即调用ls,打印当前目录的文件,子进程结束。
-
父进程接受信号,结束主进程。
理解fork的执行
现在我们来看看这一段代码:
|
|
下面是它的执行结果:
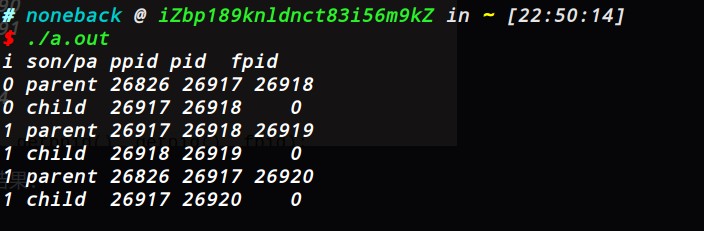
下面我们来看看为什么会有这样的结果:
1.首先父进程中,i=0时,打印0 parent 26826 26917 26918,随后父进程等待子进程执行。
子进程接着拷贝父进程(连同PC),接着父进程中i=0时fork()之后的代码运行,打印0 child 26917 26918 0,此时子进程在i=0时的fork()返回0。
子进程i=1时候的fork()接着生成一个孙子进程,并返回其pid,子进程打印1 parent 26917 26918 26919,生成的孙子进程中从i=1的fork()出接着执行,此处的fork()返回0,打印1 child 26918 26919 0。第一个子进程结束。
2.父进程中i=1时,执行fork(),生成子进程,打 印1 parent 26826 26917 26920。
子进程接着执行1=1时,fork()之后的代码,打印1 child 26917 26920 0。进程结束。
至于为什么父进程是1,这是另一方面的知识,暂且不管。
Fork里的COW机制
一开始便说了,fork执行之后,产生一个新的子进程,其子进程会复制父进程的数据与堆栈空间,并继承父进程的用户代码,组代码,环境变量、已打开的文件代码、工作目录和资源限制等。这里的复制使用了COW(Copy on Write)机制。
什么是Copy On Write
COW本质上是一种Lazy Copy的思想。
写入时复制(英语:Copy-on-write,简称COW)是一种计算机程序设计领域的优化策略。
其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的(transparently)。
此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被建立,因此多个调用者只是读取操作时可以共享同一份资源。
在使用fork创建子进程时,只有当有进程需要修改的时候才会真正的执行数据的拷贝,之后再在进程自己的数据段修改数据。否则,如果进程只有读请求的话,实际上不需要不执行资源的复制,只需要在不同进程之间维护对资源的引用即可。
fork中COW技术实现原理
fork()之后,kernel把父进程中所有的内存页的权限都设为read-only,然后子进程的地址空间指向父进程。当父子进程都只读内存时,相安无事。
当其中某个进程写内存时,CPU硬件检测到内存页是read-only的,于是触发页异常中断(page-fault),陷入kernel的一个中断例程。
中断例程中,kernel就会把触发的异常的页复制一份,于是父子进程各自持有独立的一份,之后进程再修改对应的数据。
总结
fork()会返回两次,第一次在父进程中返回fork()出的子进程的pid,第二此在子进程中返回0,接着从fork()处之后的代码开始执行。
fork()会产生一个新的子进程,其子进程会复制父进程的数据与堆栈空间,并继承父进程的用户代码,组代码,环境变量、已打开的文件代码、工作目录和资源限制等。
复制资源的核心是COW思想。
好处
- COW技术可减少分配和复制大量资源时带来的瞬间延时。
- COW技术可减少不必要的资源分配。比如fork进程时,并不是所有的页面都需要复制,父进程的代码段和只读数据段都不被允许修改,所以无需复制。
缺点
- 如果在fork()之后,父子进程都还需要继续进行写操作,那么会产生大量的分页错误(页异常中断page-fault),这样就得不偿失。