MIT6.824-RaftKV
April 15, 2022 · 1039 words · 5 min · Raft Distributed System Consensus MIT6.824
Earlier, I looked at the code of Casbin-Mesh because I wanted to try GSOC. Casbin-Mesh is a distributed Casbin application based on Raft. This RaftKV in MIT6.824 is quite similar, so I took the opportunity to write this blog.
Lab Overview
Lab 03 involves building a distributed KV service based on Raft. We need to implement the server and client for this service.
The structure of RaftKV and the interaction between its modules are shown below:
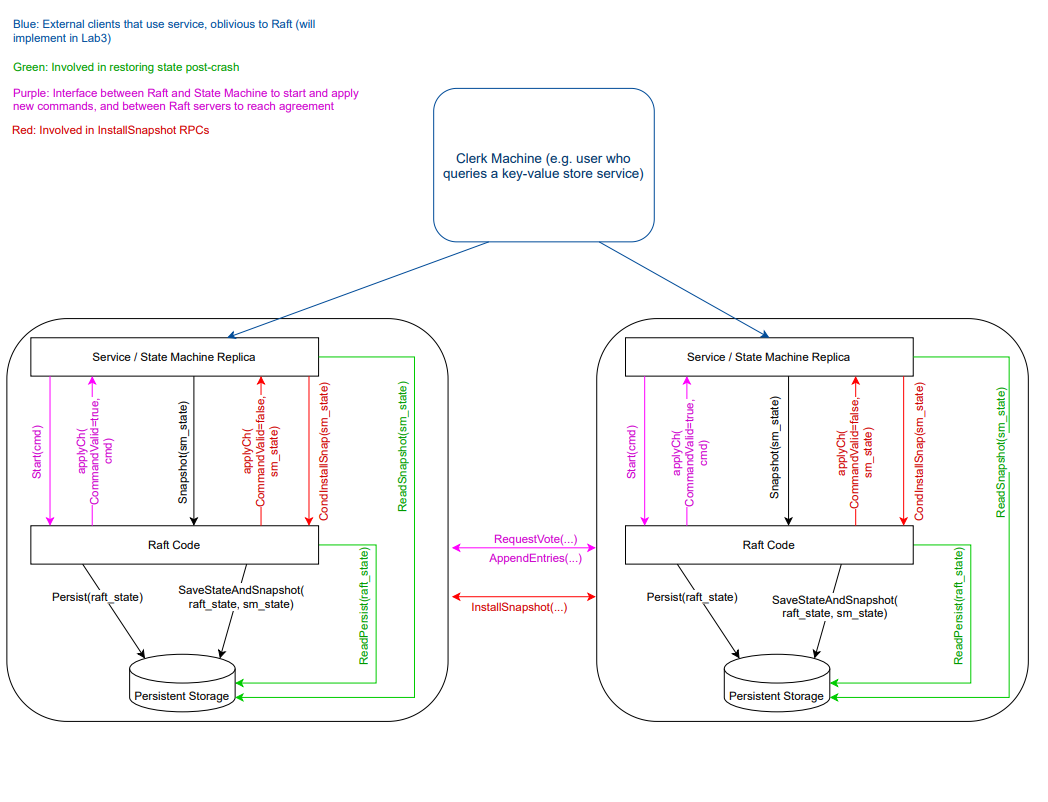
Compared to the previous lab, the difficulty is significantly lower. For implementation, you can refer to this excellent implementation, so I won’t elaborate too much.
Raft-Related Topics
Let’s talk about Raft and its interactions with clients.
Routing and Linearizability
To build a service that allows client access on top of Raft, the issues of routing and linearizability must first be addressed.
Routing
Raft is a Strong Leader consensus algorithm, and read and write requests usually need to be executed by the Leader. When a client queries the Raft cluster, it typically randomly selects a node. If that node is not the Leader, it returns the Leader information to the client, and the client redirects the request to the Leader.
Linearizability
Currently, Raft only supports At Least Once semantics. For a single client request, the Raft state machine may apply the command multiple times, which is particularly unsuitable for consensus-based systems.
To achieve linearizability, it is clear that requests need to be made idempotent.
A basic approach is for the client to assign a unique UID to each request, and the server maintains a session using this UID to cache the response of successful requests. When a duplicate request arrives at the server, it can respond directly using the cached response, thus achieving idempotency.
Of course, this introduces the issue of session management, but that is not the focus of this article.
Read-Only Optimization
After solving the above two problems, we have a usable Raft-based service.
However, we notice that whether it’s a read or write request, our application needs to go through a round of AppendEntries communication initiated by the Leader. It also requires successful quorum ACKs and additional disk write operations before the log is committed, after which the result can be returned to the client.
Write operations change the state machine, so these are necessary steps for write requests. However, read operations do not change the state machine, and we can optimize read requests to bypass the Raft log, reducing the overhead of synchronous write operations on disk IO.
The problem is that without additional measures, read-only query results that bypass the Raft log may become stale.
For example, if the old cluster Leader and a new Leader’s cluster are partitioned, queries made to the old Leader could be outdated.
The Raft paper mentions two methods to bypass the Raft log and optimize read-only requests: Read Index and Lease Read.
Read Index
The Read Index approach needs to address several issues:
- Committed logs from the old term
For example, if the old Leader commits a log but crashes before sending heartbeats, other nodes will elect a new Leader. According to the Raft paper, the new Leader does not proactively commit logs from the old Leader.
To solve this, a no-op log is committed after a new Leader is elected to commit the old log.
- Gap between
commitIndexandappliedIndex
Introduce a
readIndexvariable, where the Leader saves the currentcommitIndexin a local variable calledreadIndex. This acts as a boundary for applying the log, and when a read-only request arrives, the log must be applied up to the position recorded byreadIndexbefore the Leader can query the state machine to provide read services.
- Ensure no Leader change when providing read-only services
To achieve this, after receiving a read request, the Leader first sends a heartbeat and needs to receive quorum ACKs to ensure there is no other Leader with a higher term, thus ensuring that
readIndexis the highest committed index in the cluster.
For the specific process and optimizations like Batch and Follower Read, refer to the author’s PhD dissertation on Raft.
Lease Read
The Read Index approach only optimizes the overhead of disk IO, but still requires a round of network communication. However, this overhead can also be optimized, leading to the Lease Read approach.
The core idea of Lease Read is to use the fact that a Leader Election requires at least one ElectionTimeout time period. During this period, the system will not conduct a new election, thereby avoiding Leader changes when providing read-only services. We can use clocks to optimize network IO.
Implementation
To let the clock replace network communication, we need an additional lease mechanism. Once the Leader’s Heartbeat is approved by a quorum, the Leader can assume that no other node can become Leader during the ElectionTimeout period, and it can extend its lease accordingly. While holding the lease, the Leader can directly serve read-only queries without extra network communication.
However, there may be clock drift among servers, which means Followers cannot ensure that the Leader will not time out during the lease. This introduces the critical design for Lease Read: what strategy should be used to extend the lease?
The paper assumes that $ClockDrift$ is bounded, and when a heartbeat successfully updates the lease, the lease is extended to $start + rac{ElectionTimeout}{ClockDriftBound}$.
$ClockDriftBound$ represents the limit of clock drift in the cluster, but discovering and maintaining this limit is challenging due to many real-time factors that cause clock drift.
For instance, garbage collection (GC), virtual machine scheduling, cloud machine scaling, etc.
In practice, some safety is usually sacrificed for Lease Read performance. Generally, the lease is extended to $StartTime + ElectionTimeout - \Delta{t}$, where $\Delta{t}$ is a positive value. This reduces the lease extension time compared to ElectionTimeout, trading off between network IO overhead and safety.
Summary
When building a Raft-based service, it is crucial to design routing and idempotency mechanisms for accessing the service.
For read-only operations, there are two main optimization methods: Read Index and Lease Read. The former optimizes disk IO during read operations, while the latter uses clocks to optimize network IO.