MIT6.824-Raft
February 21, 2022 · 953 words · 5 min · Paper Reading Consensu Distributed System MIT6.824
Finally, I managed to complete Lab 02 during this winter break, which had been on hold for quite some time. I was stuck on one of the cases in Test 2B for a while. During the winter break, I revisited the implementations from experts, and finally completed all the tasks, so I decided to document them briefly.
Algorithm Overview
The basis of consensus algorithms is the replicated state machine, which means that executing the same deterministic commands in the same order will eventually lead to a consistent state. Raft is a distributed consensus algorithm that serves as an alternative to Paxos, making it easier to learn and understand compared to Paxos.
The core content of the Raft algorithm can be divided into three parts: $Leader Election + Log Replication + Safety$.
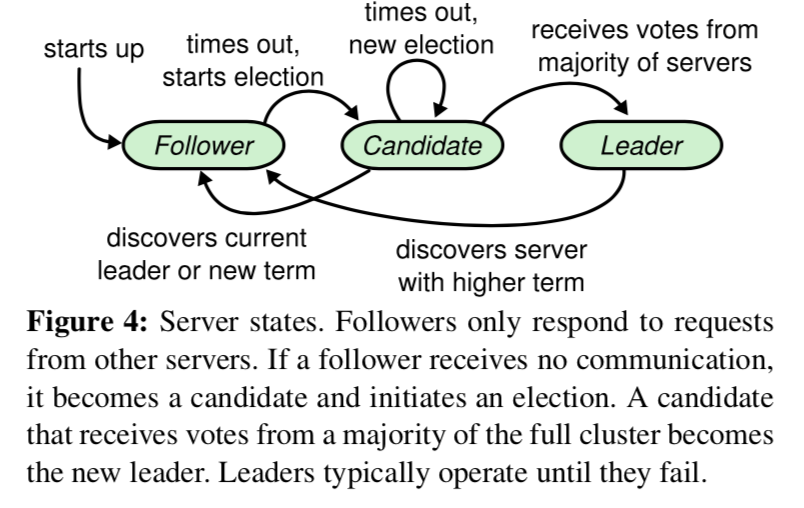
Initially, all nodes in the cluster start as Followers. If a Follower does not receive a heartbeat from the Leader within a certain period, it becomes a Candidate and triggers an election, requesting votes from the other Followers. The Candidate that receives a majority of votes becomes the Leader.
Raft is a strong leader and strongly consistent distributed consensus algorithm. It uses Terms as a logical clock, and only one Leader can exist in each term. The Leader needs to send heartbeats periodically to maintain its status and to handle log replication.
When replicating logs, the Leader first replicates the log to other Followers. Once a majority of the Followers successfully replicate the log, the Leader commits the log.
Safety mainly consists of five parts, with two core elements relevant to the implementation. One is the leader’s append-only rule, which means it cannot modify committed logs. The other is election safety, preventing split-brain scenarios and ensuring that the new Leader has the most up-to-date log.
For more details, please refer to the original paper.
Implementation Ideas
The implementation largely follows an excellent blog post (see references), and many algorithm details are also provided in Figure 2 of the original paper, so I will only focus on aspects that need attention when implementing each function.
Leader Election
Triggering Election + Handling Election Results
The election is initiated by launching multiple goroutines to send RPC requests to other nodes in the background. Therefore, when handling RPC responses, it is necessary to confirm that the current node is a Candidate and that the request is not outdated, i.e., rf.state == Candidate && req.Term == rf.currentTerm. If the election is successful, the node should immediately send heartbeats to notify other nodes of the election result.
If a failed response is received with resp.Term > rf.currentTerm, the node should switch to the Follower state, update the term, and reset voting information.
In fact, whenever the term is updated, the voting information needs to be reset. If the
votedForinformation is not reset, some tests will fail.
Request Vote RPC
First, filter outdated requests with req.Term < rf.currentTerm and ignore duplicate voting requests for the current term. Then, follow the algorithm’s logic to process the request. Note that if the node successfully grants the vote, it should reset the election timer.
Resetting the election timeout only when granting a vote helps with liveness in leader elections under unstable network conditions.
State Transition
When switching roles, be mindful of handling the state of different timers (stop or reset). When switching to Leader, reset the values of matchIndex and nextIndex.
Log Replication
Log replication is the core of the Raft algorithm, and it requires careful attention.
My implementation uses multiple replicator and applier threads for asynchronous replication and application.
Log Replication RPC
First, filter outdated requests with req.Term < rf.currentTerm. Then, handle log inconsistencies, log truncation, and duplicate log entries before replicating logs and processing commitIndex.
Trigger Log Replication + Handle Request Results
Determine whether to replicate logs directly or send a snapshot before initiating replication.
The key point in handling request results is how to update matchIndex, nextIndex, and commitIndex.
matchIndex is used to record the latest log successfully replicated on other nodes, while nextIndex records the next log to be sent to other nodes. commitIndex is updated by sorting matchIndex and determining whether to trigger the applier to update appliedIndex.
If the request fails, nextIndex should be decremented, or the node should switch to the Follower state.
Asynchronous Apply
This is essentially a background goroutine controlled by condition variables and uses channels for communication. Each time it is triggered, it sends log[lastApplied:commitIndex] to the upper layer and updates appliedIndex.
Persistence
Persist the updated attributes that need to be saved to disk in a timely manner.
Install Snapshot
The main components are the Snapshot triggered by the Leader and the corresponding RPC. When applying a Snapshot, determine its freshness and update log[0], appliedIndex, and commitIndex.
Pitfalls
Defer
The first pitfall is related to the defer keyword in Go. I like to use the defer keyword at the beginning of an RPC to directly print some data from the node: defer Dprintf("%+v", raft.currentTerm). This way, the log can be printed at the end of the call. However, the content to be printed is fixed at the time the defer statement is executed. The correct usage should be defer func(ID int) { Dprintf("%+v", id) }().
Log Dummy Header
It is best to reserve a spot in the log for storing the index and term of the snapshot to avoid a painful refactor of the Snapshot section later.
Lock
Refer to the guidance on locking suggestions. Use a single coarse-grained lock rather than multiple locks. Correctness of the algorithm is more important than performance. Avoid holding locks while sending RPCs or using channels, as it may lead to timeouts.