MIT6.824-MapReduce
January 22, 2021 · 1541 words · 8 min · MIT6.824 Distributed System Paper Reading
The third year of university has been quite intense, leaving me with little time to continue my studies on 6.824, so my progress stalled at Lab 1. With a bit more free time during the winter break, I decided to continue. Each paper or experiment will be recorded in this article.
This is the first chapter of my Distributed System study notes.
About the Paper
The core content of the paper is the proposed MapReduce distributed computing model and the approach to implementing the Distributed MapReduce System, including the Master data structure, fault tolerance, and some refinements.
MapReduce Computing Model
The model takes a series of key-value pairs as input and outputs a series of key-value pairs as a result. Users can use the MapReduce System by designing Map and Reduce functions.
- Map: Takes input data and generates a set of intermediate key-value pairs
- Reduce: Takes intermediate key-value pairs as input, combines all data with the same key, and outputs the result.
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
MapReduce Execution Process
The Distributed MapReduce System adopts a master-slave design. During the MapReduce computation, there is generally one Master and several Workers.
- Master: Responsible for creating, assigning, and scheduling Map and Reduce tasks
- Worker: Responsible for executing Map and Reduce tasks
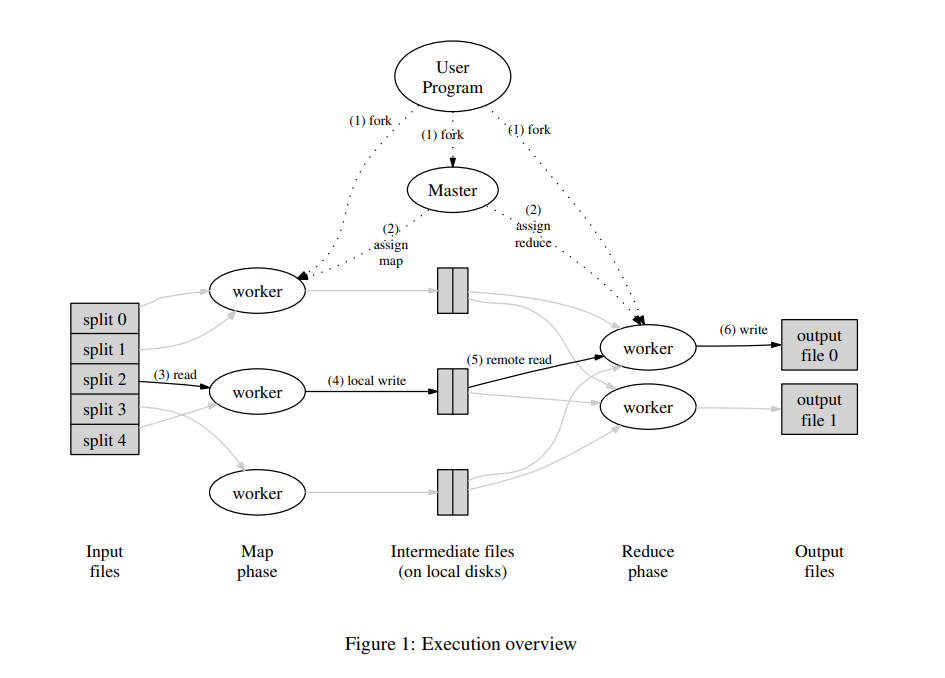
A more detailed description is as follows:
-
The entire MapReduce execution process includes M Map Tasks and R Reduce Tasks, divided into two phases: Map Phase and Reduce Phase.
-
The input file is split into M splits, and the computation enters the Map Phase. The Master assigns Map Tasks to idle Workers. The assigned Worker reads the corresponding split data and executes the Task. When all Map Tasks are completed, the Map Phase ends. The Partition function (generally
hash(key) mod R) is used to generate R sets of intermediate key-value pairs, which are stored in files and reported to the Master for subsequent Reduce Task operations. -
The computation enters the Reduce Phase. The Master assigns Reduce Tasks, and each Worker reads the corresponding intermediate key-value file and executes the Task. Once all Reduce tasks are completed, the computation is finished, and the results are stored in result files.
MapReduce Fault Tolerance Mechanism
Since Google MapReduce heavily relies on the distributed atomic file read/write operations provided by Google File System, the fault tolerance mechanism of the MapReduce cluster is much simpler and primarily focuses on recovering from unexpected task interruptions.
Worker Fault Tolerance
In the cluster, the Master periodically sends Ping signals to each Worker. If a Worker does not respond for a period of time, the Master considers the Worker unavailable.
Any Map task assigned to that Worker, whether running or completed, must be reassigned by the Master to another Worker, as the Worker being unavailable also means the intermediate results stored on that Worker’s local disk are no longer available. The Master will also notify all Reducers about the retry, and Reducers that fail to obtain complete intermediate results from the original Mapper will start fetching data from the new Mapper.
If a Reduce task is assigned to that Worker, the Master will select any unfinished Reduce tasks and reassign them to other Workers. Since the results of completed Reduce tasks are stored in Google File System, the availability of these results is ensured by Google File System, and the MapReduce Master only needs to handle unfinished Reduce tasks.
If there is a Worker in the cluster that takes an unusually long time to complete the last few Map or Reduce tasks, the entire MapReduce computation time will be prolonged, and such a Worker becomes a straggler.
Once the MapReduce computation reaches a certain completion level, any remaining tasks are backed up and assigned to other idle Workers, and the task is considered completed once one of the Workers finishes it.
Master Fault Tolerance
There is only one Master node in the entire MapReduce cluster, so Master failures are relatively rare.
During operation, the Master node periodically saves the current state of the cluster as a checkpoint to disk. After the Master process terminates, a restarted Master process can use the data stored on disk to recover to the state of the last checkpoint.
Refinement
Partition Function
Used during the Map Phase to assign intermediate key-value pairs to R files according to certain rules.
Combiner
In some situations, the user-defined Map task may generate a large number of duplicate intermediate keys. The Combiner function performs a partial merge of the intermediate results to reduce the amount of data that needs to be transmitted between Mapper and Reducer.
Experiment
The experiment involves designing and implementing the Master and Worker to complete the main functionality of a Simple MapReduce System.
In the experiment, the single Master and multiple Worker model was implemented through RPC calls, and different applications were formed by running Map and Reduce functions via Go Plugins.
Master & Worker Functionality
Master
- Task creation and scheduling
- Worker registration and task assignment
- Receiving the current state of the Worker
- Monitoring task status
Worker
- Registering with the Master
- Getting tasks and processing them
- Reporting status
Note: The Master provides corresponding functions to Workers via RPC calls
Main Data Structures
The design of data structures is the main task, and good design helps in implementing functionality. The relevant code is shown here; for the specific implementation, see GitHub.
Master
type Master struct {
// Your definitions here.
nReduce int
taskQueue chan Task
tasksContext []TaskContext
lock sync.Mutex
files []string
phase PhaseKind
done bool
workerID int
}
Worker
type worker struct {
ID int
mapf func(string, string) []KeyValue
reducef func(string, []string) string
nReduce int
nMap int
}
Task & TaskContext
type Task struct {
ID int
Filename string
Phase PhaseKind
}
type TaskContext struct {
t *Task
state ContextState
workerID int
startTime time.Time
}
Rpc Args & Reply
type RegTaskArgs struct {
WorkerID int
}
type RegTaskReply struct {
T Task
HasT bool
}
type ReportTaskArgs struct {
WorkerID int
TaskID int
State ContextState
}
type ReportTaskReply struct {
}
type RegWorkerArgs struct {
}
type RegWorkerReply struct {
ID int
NReduce int
NMap int
}
Constant & Type
const (
RUNNING ContextState = iota
FAILED
READY
IDEL
COMPLETE
)
const (
MAX_PROCESSING_TIME = time.Second * 5
SCHEDULE_INTERVAL = time.Second
)
const (
MAP PhaseKind = iota
REDUCE
)
type ContextState int
type PhaseKind int
Running and Testing
Running
# In main directory
cd ./src/main
# Master
go run ./mrmaster.go pg*.txt
# Worker
go build -buildmode=plugin ../mrapps/wc.go && go run ./mrworker.go ./wc.so
Testing
cd ./src/main
sh ./test-mr.sh
Optimization
These optimizations are some designs I thought of that could be improved when reviewing my code after completing the experiment.
Hotspot Issue
The hotspot issue here refers to a scenario where a particular data item appears frequently in the dataset. The intermediate key-value pairs generated during the Map phase can lead to a situation where one key appears frequently, resulting in excessive disk IO and network IO for a few machines during the shuffle step.
The essence of this issue is that the Shuffle step in MapReduce is highly dependent on the data.
The design purpose of Shuffle is to aggregate intermediate results to facilitate processing during the Reduce phase. Consequently, if the data is extremely unbalanced, hotspot issues will naturally arise.
In fact, the core problem is that a large number of keys are assigned to a single disk file after being hashed, serving as input for the subsequent Reduce phase.
The hash value for the same key should be identical, so the question becomes: How can we assign the same key’s hash value to different machines?
The solution I came up with is to add a random salt to the key in the Shuffle’s hash calculation so that the hash values are different, thereby reducing the probability of keys being assigned to the same machine and solving the hotspot issue.
Fault Tolerance
The paper already proposes some solutions for fault tolerance. The scenario in question is: a Worker node crashes unexpectedly and reconnects after a reboot. The Master observes the crash and reassigns its tasks to other nodes, but the reconnected Worker continues executing its original tasks, resulting in duplicate result files.
The potential issue here is that these two files may cause incorrect results. Furthermore, the reconnected Worker continuing to execute its original tasks wastes CPU and IO resources.
Based on this, we need to mark the newly generated result files, ensuring only the latest files are used as results, thus resolving the file conflict. Additionally, we should add an RPC interface for Worker nodes so that when they reconnect, the Master can call it to clear out any original tasks.
Straggler Issue
The straggler issue refers to a Task taking a long time to complete, delaying the overall MapReduce computation. Essentially, it is a hotspot issue and Worker crash handling problem, which can be addressed by referring to the above sections.
References
MapReduce: Simplified Data Processing on Large Clusters
Detailed Explanation of Google MapReduce Paper