MIT6.824 AuroraDB
August 1, 2023 · 524 words · 2 min · Distributed System Database Cloud-Native MIT6.824
This article introduces the design considerations of AWS’s database product, Aurora, including storage-compute separation, single-writer multi-reader architecture, and quorum-based NRW consistency protocol. The article also mentions how PolarDB was inspired by Aurora, with differences in addressing network bottlenecks and system call overhead.
Aurora is a database product provided by AWS, primarily aimed at OLTP business scenarios.
In terms of design, there are several aspects worth noting:
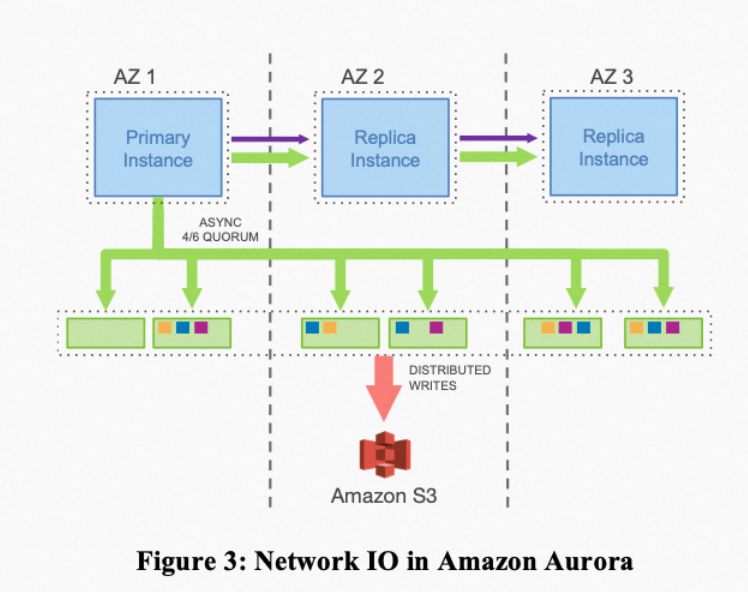
- The design premise of Aurora is that with databases moving to the cloud, thanks to advancements in cloud infrastructure, the biggest bottleneck for databases has shifted from compute and storage to the network. This was an important premise for AWS when designing Aurora. Based on this premise, Aurora revisits the concept of “Log is Database”, pushing only the RedoLog down to the storage layer.
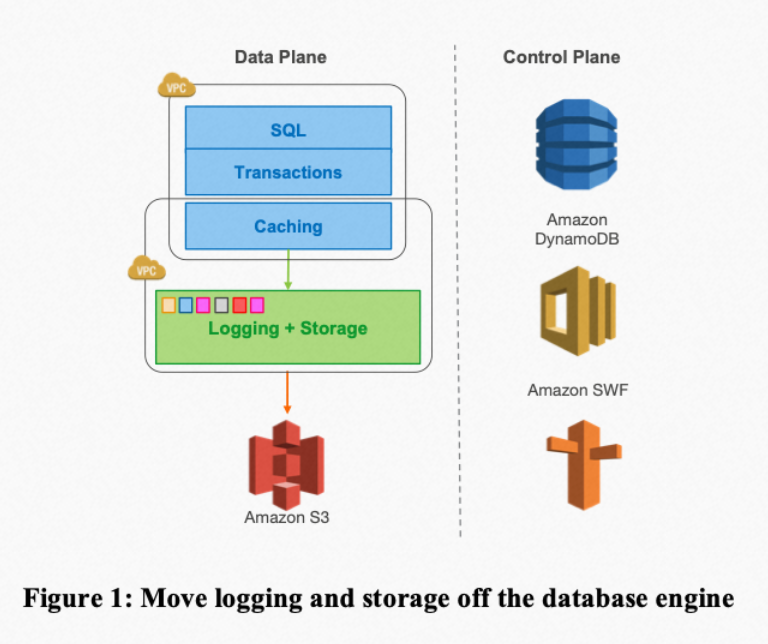
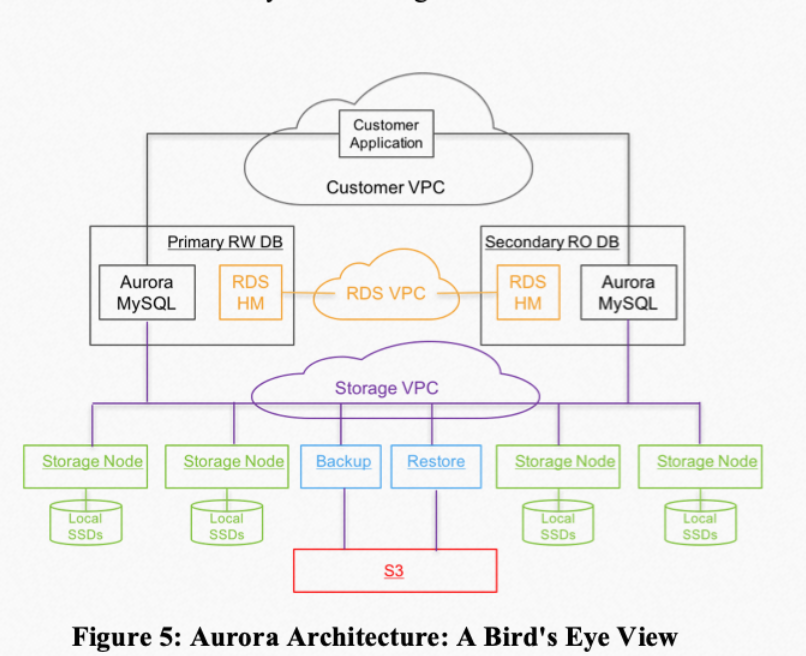
- Storage-compute separation: The database storage layer interfaces with a distributed storage system, which provides reliability and security guarantees. The compute and storage layers can scale independently. The storage system provides a unified data view to the upper layers, significantly improving the efficiency of core functions and operations (such as backup, data recovery, and high availability).
- Interesting reliability guarantees: For example, quorum-based NRW consistency protocol, where read and write operations on storage nodes require majority voting, ensures dual-AZ level fault tolerance. Sharding is used to reduce failure handling time, improving the SLA. Most reads occur during database recovery when the current state needs to be restored.
- Single-writer multi-reader: Unlike NewSQL products with a shared-nothing architecture, Aurora provides only a single write node. This simplifies data consistency guarantees since the single write node can use the RedoLog LSN as a logical clock to maintain the partial order of data updates. By pushing the RedoLog to all nodes and applying these operations in order, consistency can be achieved.
- Transaction implementation: Since the storage system provides a unified file view to the upper layer, Aurora’s transaction implementation is almost the same as that of a single-node transaction algorithm and can provide similar transaction semantics. NewSQL transactions are generally implemented via distributed transactions based on 2PC.
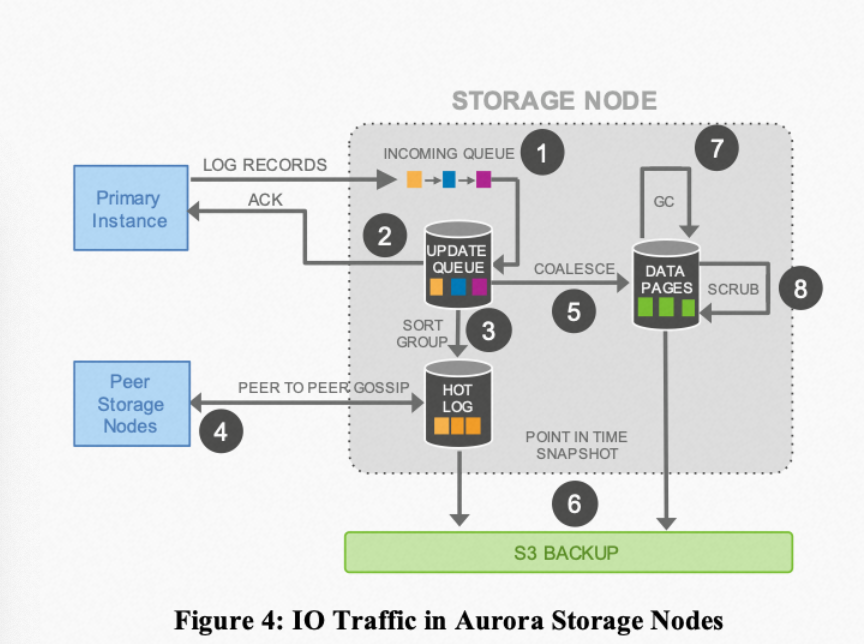
- Background acceleration for foreground processing: Similar to the approach in LevelDB, storage nodes try to make some operations asynchronous (such as log apply) to improve user-perceived performance. These asynchronous operations maintain progress using various LSNs, such as VLSN, commit-LSN, etc.
Interestingly, although PolarDB’s design was inspired by Aurora, its architectural design considers that the network is not the bottleneck but rather that various system calls through the OS slow down overall speed. Given the instability of Alibaba Cloud’s storage system at that time, PolarStore was introduced, using hardware and FUSE-based storage technology to bypass or optimize system calls. Now that Pangu has improved significantly in terms of both stability and performance, it makes sense to weaken the role of PolarStore. I think this reasoning makes sense.
Additionally, why did they choose to use NRW instead of a consensus protocol like Raft? For now, it seems that NRW has one less round of network communication compared to Raft, which might be the reason.