LevelDB Write
May 10, 2022 · 712 words · 4 min · LSM LevelDB
This is the second chapter of my notes on reading the LevelDB source code, focusing on the write flow of LevelDB. This article is not a step-by-step source code tutorial, but rather a learning note that records my questions and thoughts.
Main Process
The main write logic of LevelDB is relatively simple. First, the write operation is encapsulated into a WriteBatch, and then it is executed.
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) {
WriteBatch batch;
batch.Put(key, value);
return Write(opt, &batch);
}
WriteBatch
WriteBatch is an encapsulation of a group of update operations, which are applied atomically to the state machine. A block of memory is used to save the user’s update operations.
InMemory Format:
| seq_num: 8 bytes | count: 4 bytes | list of records{ type + key + value}
class WriteBatch {
...
// See comment in write_batch.cc for the format of rep_;
// WriteBatch::rep_ :=
// sequence: fixed64
// count: fixed32
// data: record[count]
// record :=
// kTypeValue varstring varstring |
// kTypeDeletion varstring
// varstring :=
// len: varint32
// data: uint8[len]
std::string rep_;
}
// some opt
void WriteBatch::Put(const Slice& key, const Slice& value) {
WriteBatchInternal::SetCount(this, WriteBatchInternal::Count(this) + 1);
rep_.push_back(static_cast<char>(kTypeValue));
PutLengthPrefixedSlice(&rep_, key);
PutLengthPrefixedSlice(&rep_, value);
}
Write Flow
The write operation mainly consists of four steps:
Initializing Writer
Writer actually contains all the information needed for a write operation.
// Information kept for every waiting writer
struct DBImpl::Writer {
explicit Writer(port::Mutex* mu)
: batch(nullptr), sync(false), done(false), cv(mu) {}
Status status;
WriteBatch* batch;
bool sync;
bool done;
port::CondVar cv;
};
Writer Scheduling
LevelDB’s write process is a multi-producer, single-consumer model, with multiple threads producing writers and a single thread consuming them. Each writer is produced by one thread but can be consumed by multiple threads.
Internally, LevelDB maintains a writer queue. Each thread’s write, delete, or update operation appends a writer to the end of the queue, with a lock ensuring data safety. Once a writer is added to the queue, the thread waits until it either reaches the head of the queue (is scheduled) or its operation is completed by another thread.
When consuming writers and executing the actual update operations, LevelDB optimizes the write task by merging writers of the same type (based on the sync flag).
Writing Writer Batches
- First,
MakeRoomForWriteensures that thememtablehas enough space and that the Write-Ahead Log (WAL) can guarantee a successful write. If the currentmemtablehas enough space, it is reused. Otherwise, a newmemtableand WAL are created, and the previousmemtableis converted to an immutablememtable, awaiting compaction (minor compaction is serialized). - The function also checks the number of Level 0 files and decides whether to throttle the write rate based on configurations and triggers. There are two main configurations:
- Slowdown Trigger: This trigger causes write threads to sleep, slowing down writes so that compaction tasks can proceed. It also limits the number of Level 0 files to ensure read efficiency.
- StopWritesTrigger: Stops write threads.
BuildBatchGroupmerges batches from writers of the same type starting from the head of the queue into a single batch.- The merged batch is then written first to the WAL and then to the
memtable.
Write-Ahead Log (WAL)
The WAL file is split into blocks, and each block consists of records. The format is as follows:
| Header{ checksum(4 bytes) + len(2 bytes) + type(1 byte)} | Data |
The record types are Zero, Full, First, Middle, and Last. Zero is reserved for preallocated files. Since a key-value pair might be too large and needs to be recorded in several chunks, the other four types are used accordingly.
Write Flow
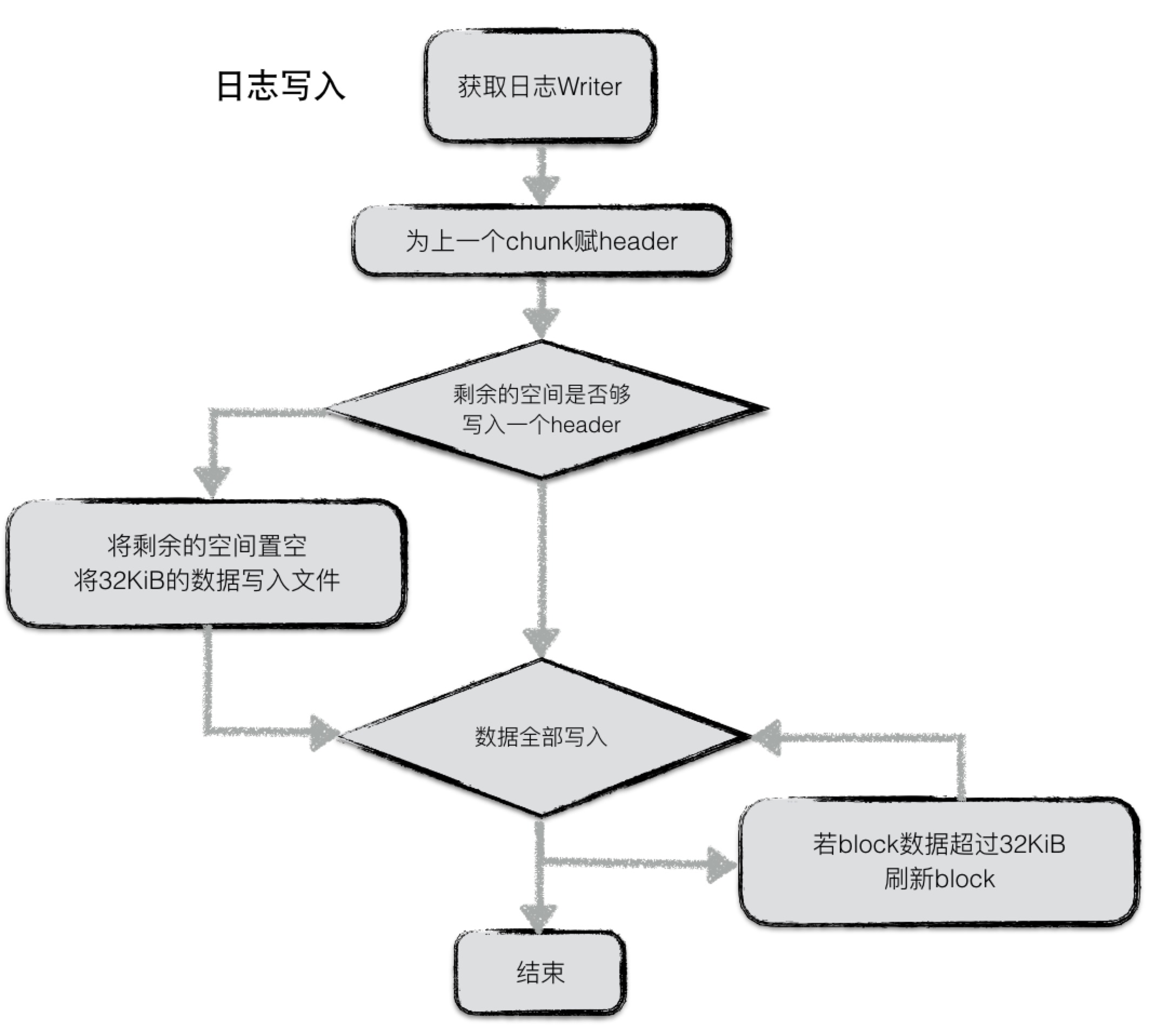
Memtable
The core design of memtable involves two parts: the skip list and the encoding of key-value pairs in the skip list. The skip list ensures the sorted nature of inserted data. For more details, you can refer to my other blog post.
The key encoded in memtable is called the Internal Key, which is encoded as follows:
| Original Key(varstring) + seq num(7 bytes) + type(1 byte) |

SeqNumis a monotonically increasing sequence number generated for each update operation, serving as a logical clock to indicate the recency of operations. Based onSeqNum, snapshot-based reads (versioned reads) can be implemented.