LevelDB Startup
April 9, 2022 · 1312 words · 7 min · LSM LevelDB
This is the first chapter of my notes on reading the LevelDB source code, focusing on the startup process of LevelDB. This article is not a step-by-step source code tutorial, but rather a learning note that records my questions and thoughts.
A code repository with annotations will be shared on GitHub later for those interested in studying it.
Prerequisites
Database Files
For now, I won’t delve into the encoding and naming details of these files (as I haven’t reached that part yet). I’ll focus on the meaning and role of each file.
├── 000005.ldb
├── 000008.ldb // sst or ldb are both sst files
├── 000009.log // WAL
├── CURRENT // Records the name of the manifest file in use, also indicates the presence of the database
├── LOCK // Empty file, ensures only one DB instance operates on the database
├── LOG // Logs printed by LevelDB
├── LOG.old
└── MANIFEST-000007 // descriptor_file, metadata file
Some questions worth exploring, which I may write about later:
- How does LOCK ensure only one DB instance holds the database?
Essentially, it uses the
fcntlsystem call to set a write lock on the LOCK file.
- Encoding issues of various files
I’ll discuss LevelDB’s encoding design in a future blog.
DB State
LevelDB is an embedded database, often used as a component in other applications (e.g., for metadata nodes in distributed storage systems). These applications may crash or exit gracefully, leaving LevelDB data files behind. Thus, it’s necessary to restore the previous database state during startup to ensure data integrity.
So, what should the DB state include? LevelDB is an LSM-based storage engine, essentially an LSM Tree data structure + various read/write and storage optimizations. Based on this and LevelDB’s documentation, the DB state includes at least the following persistent information:
- The SST files for each level and the key range covered by each SST file
The key range helps avoid unnecessary I/O.
- Global logical clock,
last_seq_numberEach data update has a
seq_numthat marks the recency of the update and is related to ordering. - Compaction-related parameters (
file_to_compact,score,point)Compaction parameters are used to trigger compaction after a crash.
- Comparator name
Once the DB is initialized, the data sorting logic is fixed and cannot be changed. The comparator name serves as a credential.
log_number,next_file_numberWAL number and the next available file number.
deleted_filesandadd_filesSST files to be deleted or added due to compaction or reference count reaching zero.
In practice, each metadata change in LevelDB (usually caused by compaction) is recorded in a VersionEdit data structure. Thus, the DB state in LevelDB is essentially initial state + list of applied VersionEdits.
Version Control
Since we mentioned VersionEdit, let’s also discuss the version control in LevelDB’s startup process, which mainly involves three data structures: Version, VersionEdit, and VersionSet.
Why is version control needed? In short, LevelDB uses the Multi-Version Concurrency Control (MVCC) mechanism to avoid using a big lock and improve performance.
Snapshot reads at the command level are implemented via sequence_number. Each operation is assigned the current sequence_number, which is used to determine the data visible to that operation. Records with a sequence_number greater than that of the command are invisible to the operation.
MVCC at the SST file level is implemented using a version chain, primarily to avoid conflicts in the following scenario: when reading a file while a background major compaction tries to delete that file.
Related Data Structures
The main data structures related to SST-level MVCC are Version, VersionEdit, and VersionSet.
Version
Represents the latest data state after startup or compaction.
class Version {
VersionSet* vset_; // VersionSet to which this Version belongs
Version* next_; // Next version in linked list
Version* prev_; // Previous version in linked list
int refs_; // Number of live refs to this version
// List of files and metadata per level
std::vector<FileMetaData*> files_[config::kNumLevels];
// Next file to compact based on seek stats (compaction due to allowed_seek exhaustion)
FileMetaData* file_to_compact_;
int file_to_compact_level_;
// Level that should be compacted next and its compaction score.
// Score < 1 means compaction is not strictly needed. These fields
// are initialized by Finalize().
double compaction_score_; // Score represents data imbalance; higher score indicates greater imbalance and compaction need.
int compaction_level_;
}
VersionSet
Manages the current runtime state of the entire DB.
class VersionSet {
Env* const env_;
const std::string dbname_;
const Options* const options_;
TableCache* const table_cache_;
const InternalKeyComparator icmp_;
uint64_t next_file_number_;
uint64_t manifest_file_number_;
uint64_t last_sequence_;
uint64_t log_number_;
uint64_t prev_log_number_; // 0 or backing store for memtable being compacted
// Opened lazily
WritableFile* descriptor_file_; // descriptor_ is for manifest file
log::Writer* descriptor_log_; // descriptor_ is for manifest file
Version dummy_versions_; // Head of circular doubly-linked list of versions.
Version* current_; // == dummy_versions_.prev_
// Per-level key at which the next compaction at that level should start.
// Either an empty string, or a valid InternalKey.
std::string compact_pointer_[config::kNumLevels];
}
VersionEdit
Encapsulates metadata changes. This encapsulation reduces the window for version switching.
class VersionEdit {
/** other code */
typedef std::set<std::pair<int, uint64_t>> DeletedFileSet;
std::string comparator_;
uint64_t log_number_;
uint64_t prev_log_number_;
uint64_t next_file_number_;
SequenceNumber last_sequence_;
bool has_comparator_;
bool has_log_number_;
bool has_prev_log_number_;
bool has_next_file_number_;
bool has_last_sequence_;
std::vector<std::pair<int, InternalKey>> compact_pointers_;
DeletedFileSet deleted_files_;
std::vector<std::pair<int, FileMetaData>> new_files_;
};
Manifest Content
As mentioned earlier, the manifest is LevelDB’s metadata file that stores the persistent state of the database. During startup, LevelDB may need to restore the previous DB state using existing data files. Additionally, when a version changes, LevelDB generates a VersionEdit. The metadata changes recorded by VersionEdit need to be persisted to the manifest to ensure LevelDB’s MVCC multi-version state is crash-safe. Thus, the encoding layout inside the manifest is crucial.
Internally, metadata is encoded as SnapshotSessionRecord + list of SessionRecords, essentially initial state + list of applied VersionEdits.
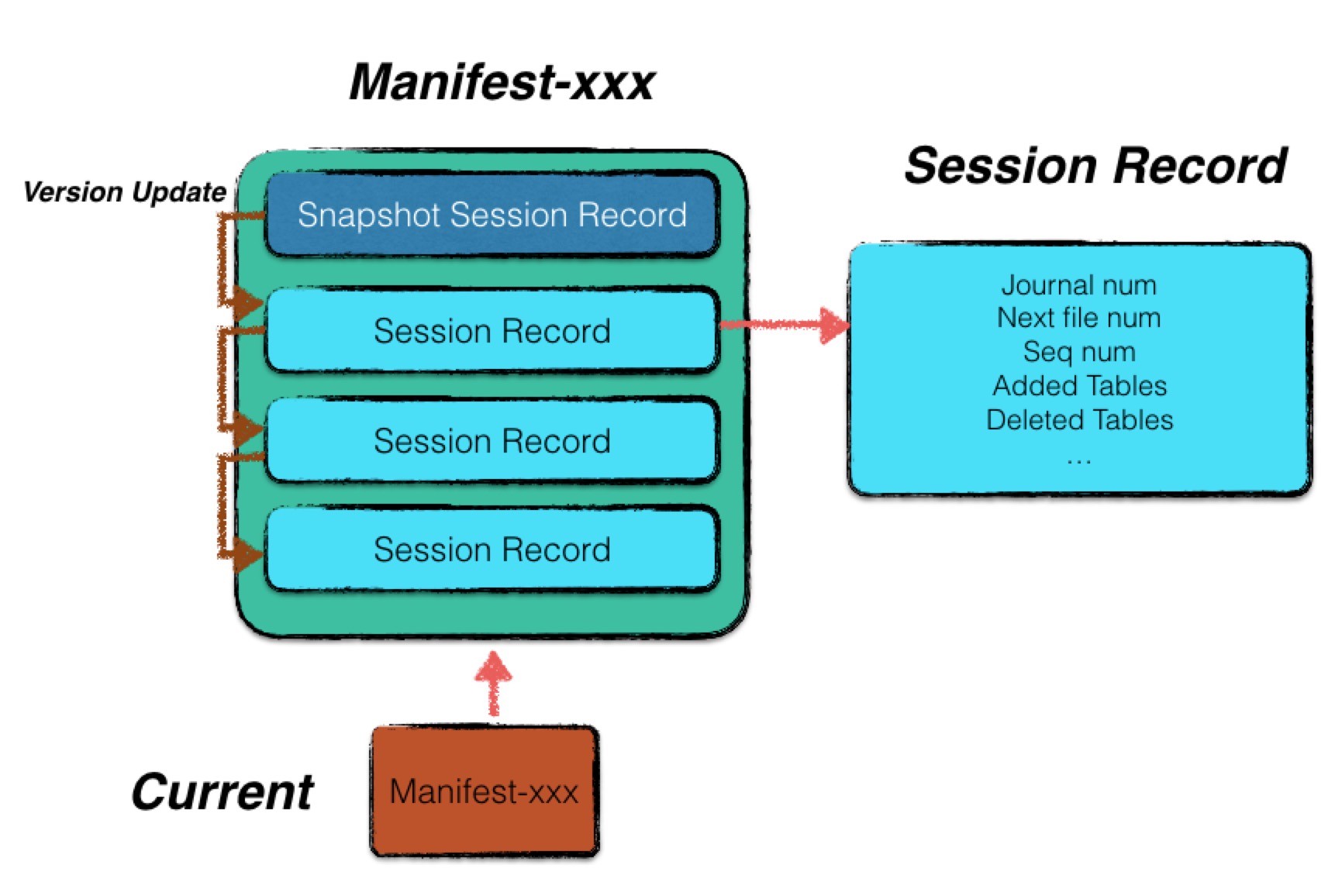
A manifest contains several session records. The first session record stores the full version information of LevelDB at that time, while subsequent session records only record incremental changes.
A session record may contain the following fields:
- Comparer name
- Latest WAL file number
- Next available file number
- The largest
sequence numberamong the data persisted by the DB- Information on new files
- Information on deleted files
- Compaction record information
Writing Version Changes to the Manifest
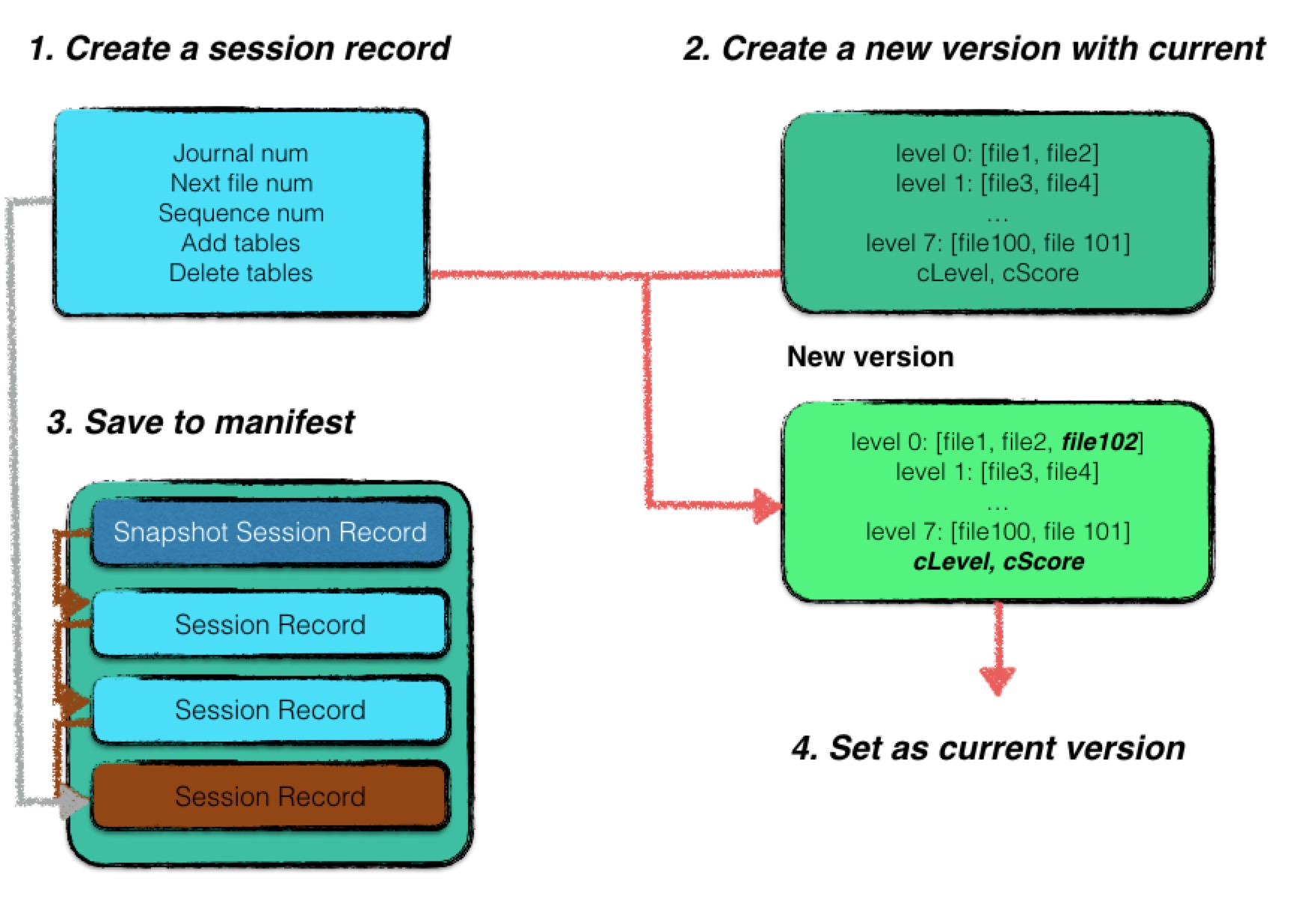
For LevelDB, adding or deleting some SSTable files needs to be an atomic operation to maintain database consistency before and after the state change.
Atomicity
Atomicity means that the operation is complete only when a session record is fully written to the manifest. If the process crashes before completion, the database can be restored to a correct state on restart, and those useless SSTable files will be deleted with compaction resumed.
Consistency
Consistency is ensured by marking state changes with version updates, which occur at the very end of the process. Thus, the database always transitions from one consistent state to another.
Restoring DB from the Manifest
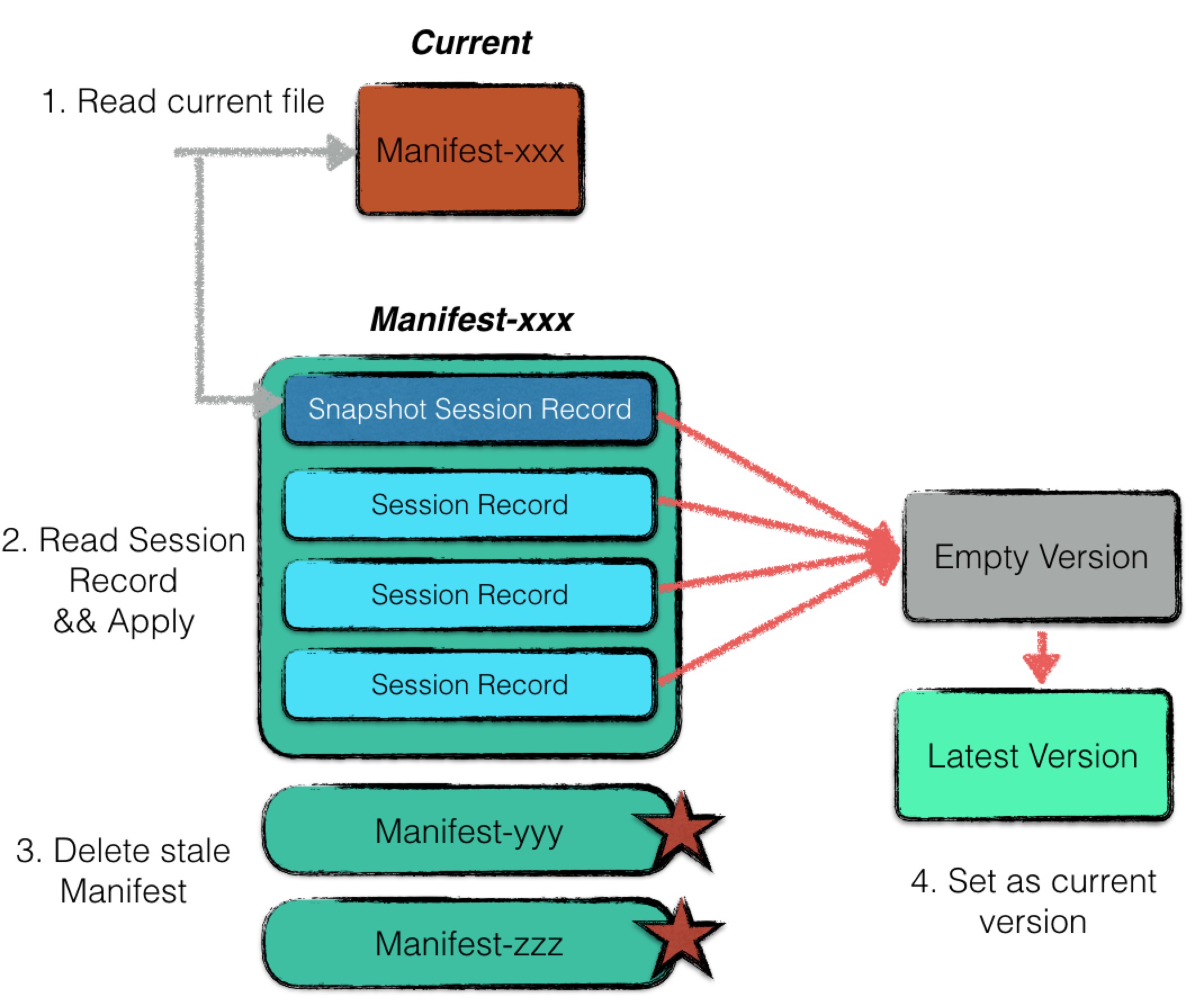
As LevelDB runs, the number of session records in a manifest grows. Therefore, each time LevelDB restarts, a new manifest is created, and the first session record captures a snapshot of the current version state.
Outdated manifests are deleted during the recovery process at the next startup.
LevelDB uses this method to control the size of the manifest file. However, if the database is not restarted, the manifest will keep growing.
DB State Recovery Process
- Check lock status and create data directory.
- Check
lockfileto determine if another DB instance exists. - Check if the
CURRENTfile exists. - Restore metadata from the manifest.
- Recover
last_seq_numberandfile_numberfrom the WAL.
Main Open Process
- Create default DB and
VersionEditinstances. - Acquire lock.
- Restore metadata from manifest and WAL.
- If the new DB instance does not have a
memtable, create one along with a WAL file. - Apply
VersionEditand persist it to the manifest. - Attempt to delete obsolete files.
- Attempt to compact data.