Kylin Overview
November 10, 2021 · 803 words · 4 min · Thesis OLAP DB Distributed System Differential Privacy Kylin
Previously, I was hoping to work on an interesting thesis, but I couldn’t find a suitable advisor nearby. I initially found a good advisor before the college started the topic selection, but it turned out they couldn’t take me on. However, I wasn’t that interested in the advisor’s field, so I decided to look for something else. Recently, the college’s thesis selection process started, and I found an interesting topic in the list. I reached out to the professor and took on the project.
The topic I chose is “Design and Implementation of Database Query Algorithms Based on Differential Privacy”, focusing on Differential Privacy + OLAP. Specifically, it’s about adding Differential Privacy as a feature to Kylin.
That’s the overall gist; as for the details, I might write about them in future blog posts. This is the first in this series of blog posts.
Introduction
Kylin is a distributed OLAP data warehouse based on columnar storage systems like HBase and Parquet, and computational frameworks like Hadoop and Spark. It supports multidimensional analysis of massive datasets.
Kylin uses a cube pre-computation method, transforming real-time queries into queries against precomputed results, utilizing idle computation resources and storage space to optimize query times. This can significantly reduce query latency.
Background
Before Kylin, Hadoop was commonly used for large-scale data batch processing, with results stored in columnar storage systems like HBase. The related technologies for OLAP included big data parallel processing and columnar storage.
-
Massive Parallel Processing: It leverages multiple machines to process computational tasks in parallel, essentially using linear growth in computing resources to achieve a linear decrease in processing time.
-
Columnar Storage: Stores data in columns instead of rows. This approach is particularly effective for OLAP queries, which typically involve aggregations of specific columns. Columnar storage allows querying only the necessary columns and makes effective use of sequential I/O, thus improving performance.
These technologies enabled minute-level SQL query performance on platforms like Hadoop. However, even this is insufficient for interactive analysis, as the latency is still too high.
The core issue is that neither parallel computing nor columnar storage changes the fundamental time complexity of querying; they do not break the linear relationship between query time and data volume. Therefore, the only optimization comes from increasing computing resources and exploiting locality principles, both of which have scalability and theoretical bottlenecks as data grows.
To address this, Kylin introduced a pre-computation strategy, building multidimensional cubes for different dimensions and storing them as data tables. Future queries are made directly against these precomputed results. With pre-computation, the size of the materialized views is determined only by the cardinality of the dimensions and is no longer linearly proportional to the size of the dataset.
Essentially, this strategy uses idle computational resources and additional storage to improve response times during queries, breaking the linear relationship between query time and data size.
Core Concepts
The core working principle of Apache Kylin is MOLAP (Multidimensional Online Analytical Processing) Cube technology.
Dimensions and Measures
Dimensions refer to perspectives used for aggregating data, typically attributes of data records. Measures are numerical values calculated based on data. Using dimensions, you can aggregate measures, e.g., $$D_1,D_2,D_3,… \rightarrow S_1,S_2,…$$
Cube Theory
Data Cube involves building and querying precomputed, multidimensional data indices.
- Cuboid: The data calculated for a particular combination of dimensions.
- Cube Segment: The smallest building block of a cube. A cube can be split into multiple segments.
- Incremental Cube Building: Typically triggered based on time attributes.
- Cube Cardinality: The cardinality of all dimensions in a cube determines the cube’s complexity. Higher cardinality often leads to cube expansion (amplified I/O and storage).
Architecture Design
Kylin consists of two parts: online querying and offline building.
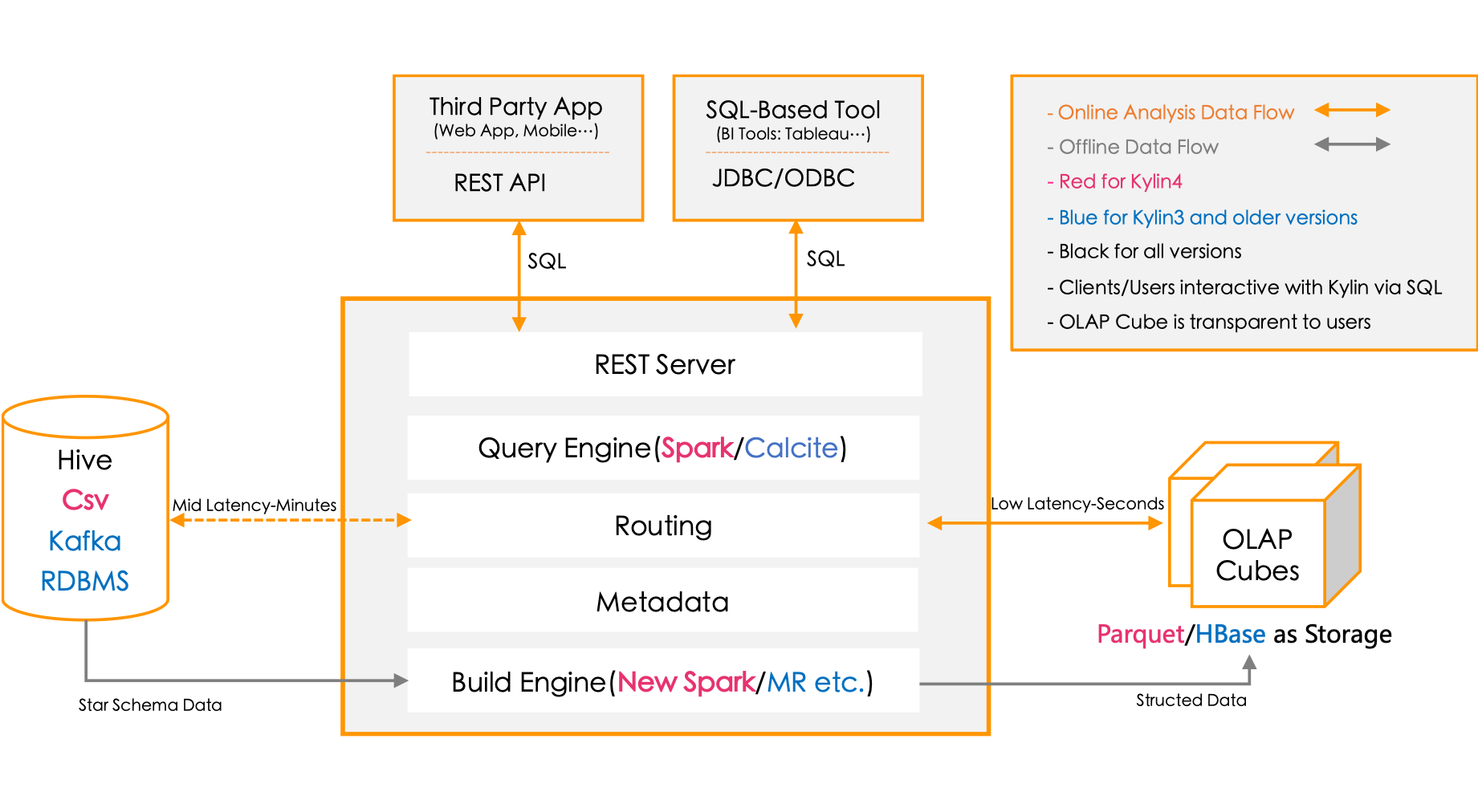
- Offline Building: Involves three main components: the data source, the build engine, and the storage engine. Data is fetched from the data source, cubes are built, and they are stored in the columnar storage engine.
- Online Querying: Consists of an interface layer and a query engine, abstracting away concepts like cubes from the user. External applications use the REST API to submit queries, which are processed by the query engine and returned.
Summary
As an OLAP engine, Kylin leverages parallel computing, columnar storage, and pre-computation techniques to improve both online query and offline build performance. This has the following notable pros and cons:
Advantages
- Standard SQL Interface: Supports BI tools and makes integration easy.
- High Query Speed: Queries against precomputed results are very fast.
- Scalable Architecture: Easily scales to handle increasing data volumes.
Disadvantages
- Complex Dependencies: Kylin relies on many external systems, which can make operations and maintenance challenging.
- I/O and Storage Overhead: Pre-computation and cube building can lead to amplified I/O and storage needs.
- Limited by Data Models: The complexity of data models and cube cardinality can impose limitations on scalability.