Apache-Iceberg Quick Investigation
October 5, 2022 · 1208 words · 6 min · Lake House Storage Big Data
- A table format for large-scale analysis of datasets.
- A specification for organizing data files and metadata files.
- A schema semantic abstraction between storage and computation.
- Developed and open-sourced by Netflix to enhance scalability, reliability, and usability.
Background
Issues encountered when migrating HIVE to the cloud:
- Dependency on List and Rename semantics makes it impossible to replace HDFS with cheaper OSS.
- Scalability issues: Schema information in Hive is centrally stored in metastore, which can become a performance bottleneck.
- Unsafe operations, CBO unfriendly, etc.
Features
- Supports secure and efficient schema, partition changes, and evolution, self-defined schema, hidden partition.
- Abstracts its own schema, not tied to any computation engine schema; partition is maintained at the schema level. Partition and sort order provide transformer functions, such as date(timestamp).
- Supports object storage with minimal dependency on FS semantics.
- ACID semantics support, parallel reads, serialized write operations:
- Separation of read and write snapshots.
- Optimistic handling of write parallel conflicts, retry to ensure writes.
- Snapshot support:
- Data rollback and time travel.
- Supports snapshot expiration (by default, data files are not deleted, but customizable deletion behavior is available) (related API doc).
- Incremental reading can be achieved by comparing snapshot differences.
- Query optimization-friendly: predicate pushdown, data file statistics. Currently, compaction is not supported, but invalid files can be deleted during snapshot expiration (deleteWith).
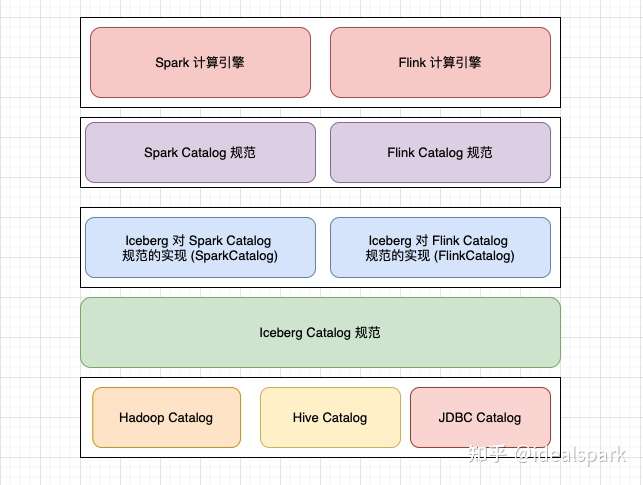
- High abstraction level, easy for modification, optimization, and extension. Catalog, read/write paths, file formats, storage dependencies are all pluggable. Iceberg’s design goal is to define a standard, open, and general data organization format while hiding differences in underlying data storage formats, providing a unified operational API for different engines to connect through its API.
- Others: file-level encryption and decryption.
Ecosystem
- Community support for OSS, Flink, Spark, and Presto:
- Flink (detail): Supports streaming reads and writes, incremental reads (based on snapshot), upsert write (0.13.0-release-notes).
- Presto: Iceberg connector.
- Aliyun OSS: # pr 3689.
- Integration with other components:
- Integration with lower storage layers: Only relies on three semantics: In-place write, Seekable reads, Deletes, supports AliOSS (# pr 3689).
- Integration with other file formats: High abstraction level, currently supports Avro, Parquet, ORC.
- Catalog: Customizable (Doc: Custom Catalog Implementation), currently supports JDBC, Hive Metastore, Hadoop, etc.
- Integration with computation layer: Provides native JAVA & Python APIs, with a high level of abstraction, supporting most computation engines.
- Open and neutral community, allowing contributions to improve influence.
Table Specification
Specification for organizing data files and metadata files.

Case: Spark + Iceberg + Local FS
Iceberg supports Parquet, Avro, ORC file formats.
# Storage organization
test2
├── data
│ ├── 00000-1-ccff6767-12cc-481c-93fc-db9f1a57438c-00001.parquet
│ └── 00001-2-6c1e5a0b-89fe-4e77-b90a-1773a7fbbcc8-00001.parquet
└── metadata
├── 2c1dc0e8-1843-4cb9-9c55-ae43f800bf3f-m0.avro // manifest file
├── snap-8512048775051875497-1-2c1dc0e8-1843-4cb9-9c55-ae43f800bf3f.avro // manifest list file
├── v1.metadata.json // metadata file
├── v2.metadata.json
└── version-hint.text // catalog
DataFile
Data files in columnar format: Parquet, ORC.
There are three types of Data Files: data file, partition delete file, equality delete file.
Manifest File
Indexes data files, including statistics and partition information.
[
{
"status":1,
"snapshot_id":{
"long":1274364374047997583
},
"data_file":{
"file_path":"/tmp/warehouse/db/test3/data/id=1/00000-31-401a9d2e-d501-434c-a38f-5df5f08ebbd7-00001.parquet",
"file_format":"PARQUET",
"partition":{
"id":{
"long":1
}
},
"record_count":1,
"file_size_in_bytes":643,
"block_size_in_bytes":67108864,
"column_sizes":{
"array":[
{
"key":1,
"value":46
},
{
"key":2,
"value":48
}
]
},
"value_counts":{
"array":[
{
"key":1,
"value":1
},
{
"key":2,
"value":1
}
]
},
"null_value_counts":{
"array":[
{
"key":1,
"value":0
},
{
"key":2,
"value":0
}
]
},
"nan_value_counts":{
"array":[
]
},
"lower_bounds":{
"array":[
{
"key":1,
"value":"\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key":2,
"value":"a"
}
]
},
"upper_bounds":{
"array":[
{
"key":1,
"value":"\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key":2,
"value":"a"
}
]
},
"key_metadata":null,
"split_offsets":{
"array":[
4
]
},
"sort_order_id":{
"int":0
}
}
},
{
// another data file meta
}
]
Snapshot
- Represents the state of a Table at a specific point in time, saved via a Manifest List File.
- A new Snapshot is generated every time a data change is made to the Table.
Manifest List File
- Contains information about all Manifest files in a Snapshot, as well as partition stats and data file count.
- One Snapshot corresponds to one Manifest List File, and each submission generates a manifest list file.
- Optimistic concurrency: when concurrent Snapshot submissions conflict, the later submission retries to ensure submission.
Each manifest list stores metadata about manifests, including partition stats and data file counts.
[
{
"manifest_path":"/tmp/warehouse/db/test3/metadata/f22b748f-a7bc-4e4c-ad6c-3e335c1c0c2b-m0.avro",
"manifest_length":6019,
"partition_spec_id":0,
"added_snapshot_id":{
"long":1274364374047997583
},
"added_data_files_count":{
"int":2
},
"existing_data_files_count":{
"int":0
},
"deleted_data_files_count":{
"int":0
},
"partitions":{
"array":[
{
"contains_null":false,
"contains_nan":{
"boolean":false
},
"lower_bound":{
"bytes":"\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
"upper_bound":{
"bytes":"\u0002\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}
}
]
},
"added_rows_count":{
"long":2
},
"existing_rows_count":{
"long":0
},
"deleted_rows_count":{
"long":0
}
},
{
// another manifest file
}
]
Metadata File
Tracks the state of the table. When the state changes, a new metadata file is generated and replaces the previous one, ensuring atomicity.
The table metadata file tracks the table schema, partitioning config, custom properties, and snapshots of the table contents.
{
"format-version":1,
"table-uuid":"175d0b61-8507-40b2-9c19-3338b05f3d48",
"location":"/tmp/warehouse/db/test3",
"last-updated-ms":1653387947819,
"last-column-id":2,
"schema":{
"type":"struct",
"schema-id":0,
"fields":[
{
"id":1,
"name":"id",
"required":false,
"type":"long"
},
Object{...}
]
},
"current-schema-id":0,
"schemas":[
{
"type":"struct",
"schema-id":0,
"fields":[
{
"id":1,
"name":"id",
"required":false,
"type":"long"
},
Object{...}
]
}
],
"partition-spec":[
{
"name":"id",
"transform":"identity",
"source-id":1,
"field-id":1000
}
],
"default-spec-id":0,
"partition-specs":[
{
"spec-id":0,
"fields":[
{
"name":"id",
"transform":"identity",
"source-id":1,
"field-id":1000
}
]
}
],
"last-partition-id":1000,
"default-sort-order-id":0,
"sort-orders":[
{
"order-id":0,
"fields":[
]
}
],
"properties":{
"owner":"chenlan"
},
"current-snapshot-id":1274364374047997700,
"snapshots":[
{
"snapshot-id":1274364374047997700,
"timestamp-ms":1653387947819,
"summary":{
"operation":"append",
"spark.app.id":"local-1653381214613",
"added-data-files":"2",
"added-records":"2",
"added-files-size":"1286",
"changed-partition-count":"2",
"total-records":"2",
"total-files-size":"1286",
"total-data-files":"2",
"total-delete-files":"0",
"total-position-deletes":"0",
"total-equality-deletes":"0"
},
"manifest-list":"/tmp/warehouse/db/test3/metadata/snap-1274364374047997583-1-f22b748f-a7bc-4e4c-ad6c-3e335c1c0c2b.avro",
"schema-id":0
}
],
"snapshot-log":[
{
"timestamp-ms":1653387947819,
"snapshot-id":1274364374047997700
}
],
"metadata-log":[
{
"timestamp-ms":1653387937345,
"metadata-file":"/tmp/warehouse/db/test3/metadata/v1.metadata.json"
}
]
}
Catalog
Records the latest metadata file path.
Features
- ACID semantics guarantee: Atomic table state changes + snapshot-based reads and writes.
- Flexible partition management: hidden partition, seamless partition changes.
- Supports incremental reads: incremental read of each change using snapshots.
- Multi-version data: beneficial for data rollback.
- No side effects, safe schema, and partition changes.
Data Types
Data files in different formats define different types.
-
Nested Types:
- struct: A tuple of typed values.
- list: A collection of values with an element type.
- map: A collection of key-value pairs with a key type and a value type.
-
Primitive Types:
| Primitive type | Description | Requirements |
|---|---|---|
| boolean | True or false | |
| int | 32-bit signed integers | Can promote to long |
| long | 64-bit signed integers | |
| float | 32-bit IEEE 754 floating point | Can promote to double |
| double | 64-bit IEEE 754 floating point | |
| decimal(P,S) | Fixed-point decimal; precision P, scale S | Scale is fixed [1], precision must be 38 or less |
| date | Calendar date without timezone or time | |
| time | Time of day without date, timezone | Microsecond precision [2] |
| timestamp | Timestamp without timezone | Microsecond precision [2] |
| timestamptz | Timestamp with timezone | Stored as UTC [2] |
| string | Arbitrary-length character sequences | Encoded with UTF-8 [3] |
| uuid | Universally unique identifiers | Should use 16-byte fixed |
| fixed(L) | Fixed-length byte array of length L | |
| binary | Arbitrary-length byte array |
Read & Write Paths
select: catalog -> manifest list file -> manifest file -> data file -> data group.
insert: reverse (catalog -> manifest list file -> manifest file -> data file -> data group).
update: delete & insert, data file + partition delete file + equality delete file.
Using Partition delete file transaction: issue of repeatedly inserting and deleting the same row within a transaction.
delete: row-level delete.
References
Flink+Iceberg Data Lake Construction
Construction Practice of Real-time Data Warehouse with Flink + Iceberg (Chinese)
Building Enterprise-grade Real-time Data Lake with Flink + Iceberg
How Flink Analyzes CDC Data in Iceberg Real-time Data Lake
Comparison of Delta, Iceberg, and Hudi Open-source Data Lake Solutions